Extracting useful information from documents with Named Entity Recognition
Categories:
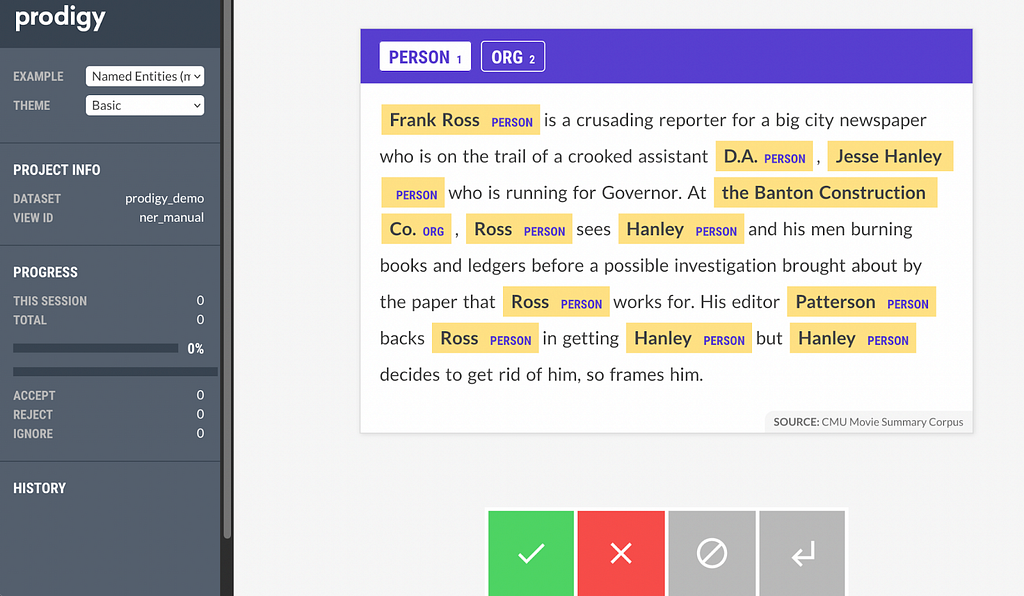
One of the most common use cases for Natural Language Processing (NLP) is to extract entities from documents. By an entity I mean a discrete thing such as a product, person, or a location. By documents, I mean an arbitrary text, for example a contract, a company report, or an academic paper. We call this task Named Entity Recognition (NER).
Named Entity Recognition
At Mantis, we’ve worked on NER problems for numerous clients in a range of sectors, for example extracting key dates, values, and jurisdictions from contracts; or extracting items, prices, and quantities from tender documents.
Most recently we worked with The Wellcome Trust (hereafter Wellcome), a large Charitable Foundation that funds science to improve people’s lives across the globe, to extract entities from funding applications. This blog post is an abridged version of a blog post we jointly wrote with Wellcome about the project, which you can read here.
Wellcome grant applications
Wellcome holds a database of over 130,000 applications predominantly from scientists applying for research funding. A lot of information about the planned research is captured in free text fields, such as the title of the application, and a synopsis of the research to be undertaken.
These free text fields are not easy to analyze, but we can use NER methods to extract some of the critical information. Wellcome stakeholders were particularly interested in geographic information, which will help them to answer questions like: who are the beneficiaries of the research funding, i.e. the people who derive ultimate benefit from the research, aside from the people and institutions that receive the funding. So, we worked with them to develop a solution to extract entities such as cities, countries, and geographic landmarks.
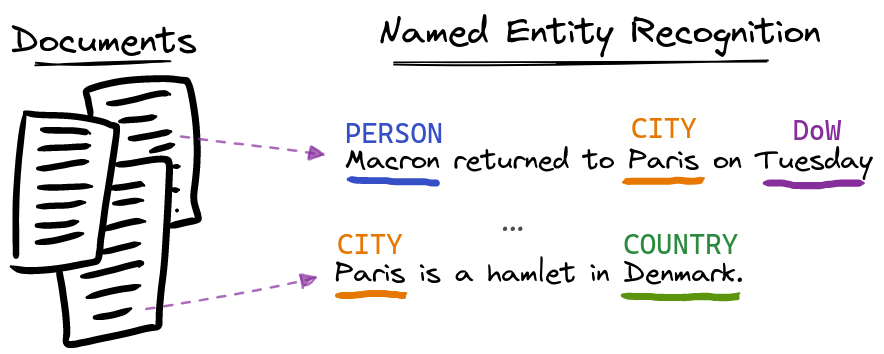
Paris is a hamlet in Denmark, who knew?
We experimented with a number of approaches, starting with the simplest possible solution which exactly matched obvious location entities such as Paris, France, and Denmark. This ‘naive’ approach is very quick to implement, and gives us a good baseline. We also explored two machine learning approaches using pre-trained models that provide a more state of the art solution.
We’ve built an application to demonstrate a machine learning approach to this problem. It uses a pre-trained transformer model (a modern type of neural network) to identify two types of location entities: geopolitical entities or GPEs (countries, administrative regions, cities, etc.) and locations (non GPE locations such as geographical regions, mountains, lakes, etc.). The application uses Wellcome grant data published openly through the website https://www.threesixtygiving.org/ under a CC BY 4.0 license.

You can experiment with our LocationFinder demonstraction app here: https://huggingface.co/spaces/mantisnlp/LocationFinder
If you experiment with the model, you’ll notice that it makes mistakes: sometimes it misses locations, and other times it will make incorrect suggestions. This is expected; Wellcome grant applications come from a very specific domain for which this generic model is not specialized.
Balancing Precision and Recall
In this project, the machine learning approaches we tried had a good balance of precision and recall. That is to say that they were reasonably good at finding location entities (high recall), but they produced quite a few false positives (low precision). The naive approach on the other hand, produces close to zero false positives (high precision), but it missed a lot of locations, because it will only find locations on the list we have given it (low recall).
The need to balance precision and recall is common to all machine learning problems, and the relative weight given to each will depend on the use case. In this project it was more important to ensure that we added data of the highest quality to Wellcome’s database, so we implemented the naive solution to begin with. In future we can improve the performance of the machine learning models for this domain by ‘fine-tuning’ them using human annotated data, something that was not available for this project.
35% more locations
Despite using a naive approach our work with Wellcome increased the useful location information available to grants by around 35%. This new information can help Wellcome’s analysts to answer important questions like: who are the beneficiaries of the research funding, i.e. the people who derive ultimate benefit from the research, aside from the people and institutions that receive the funding. For details on why this is a hard question to answer, see our other blog post written in collaboration with Wellcome.
Finally, if you need to extract some information from documents, whether they are entities or something more complex, we may be able to help. Feel free to reach out to us for a chat at hi@mantisnlp.com. You can also find me on twitter at @m_a_upson.
Extracting useful information from documents with Named Entity Recognition was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.