Automatic Prompt Engineering (Part IV: Hands-on: Evaluation)
Categories:
This is the last post of the Automatic Prompt Engineering for Retrieval-Augmented Generative Models series, where we cover how to implement an Automatic Prompt Engineering workflow to improve your prompts on a specific use: Retrieval-Augmented Generative Models. We highly recommend taking a look at the previous posts of this series (Part I, Part II and Part III) before continuing with this blog post.
At the end of Part III, we had a series of answers A given a prompt P, obtained by integrating a question Q in the prompt, and leveraging pieces of knowledge K from a Vector Store.
In Part IV, we are going to showcase how to evaluate which prompts provide better quality answers, and wrap up the topic with some conclusions.
One question remains though: How do we evaluate if the prompt P is good given the answers A I get?
8. Evaluating the answers
For every question Q I get an answer A using knowledge K. Now, I’m going to run an evaluation on each of those answers. Let’s create a class and a method to do that, evaluator.get_evaluation.
for answer in answers:
evaluation = evaluator.get_evaluation(config.EVALUATION_PROMPT_TEMPLATE,
{ ‘question’: answer[‘question’],
‘knowledge’: answer[‘knowledge’],
‘answer’: answer[‘answer’]
})
We are using another prompt called the Evaluation Prompt, in order to ask a LLM to return different evaluation scores given Q, K and A, (the different metrics we described in the previous blog posts). The prompt used for evaluation (config.EVALUATION_PROMPT_TEMPLATE) is the following:
You are an evaluator. I will provide you with a question, knowledge and an answer. I will also provide a question for each of those metrics, and you will return 1 if the answer is positive, 0 if negative, as a score for that metric. Just answer with the name of the metric and the score, nothing else.
Question:
{question}
Knowledge:
{knowledge}
Answer:
{answer}
Metrics:
- Explicit: Is the question contained explicitly in the answer or has a literal mention to parts or it?
- Helpfulness: Does the provided answer really help answer and support or contradict the question?
- Directness: Does the provided answer support the question directly?
- Grammaticality: Is the answer grammatically correct and complete?
- Relevance: Is the answer relevant to the question and covers the same topics and no other topics?
- Edge: Does the answer contain edge cases?
- Factuality: Does the answer only provide facts from the knowledge and nothing else?
- Supposition: Does the answer contain a conclusion or supposition extracted by analyzing the knowledge?
- Objectivity: Is the answer provided totally objective given what is expressed in the knowledge?
- Creativity: What is the level of creativity present in the answer given the question?
- ThirdPartyOpinion: Does the answer contain a third-party opinion?
- Source: Does the answer provide the source of information?
If we add our Question Q, Knowledge K, Answer A to the Evaluation Prompt, and send it to GPT3.5, this is what comes back:
Explicit: 60
Helpfulness: 40
Directness: 20
Grammaticality: 80
Relevance: 70
Edge: 0
Factuality: 100
Supposition: 0
Objectivity: 100
Creativity: 10
ThirdPartyOpinion: 0
Source: 0
We can parse the responses (metric and score):
evaluation_text = evaluation[‘text’].split('\n')
for row in evaluation_text:
metric_name = row.split(':')[0].strip()
value = int(row.split(':')[1].strip())
if metric_name not in metrics:
metrics[metric_name] = []
metrics[metric_name].append(value)
As you may have noticed, we are storing all the metrics in an array, because we don’t only run the prompt with 1 answer, but with all N answers we got from our different questions. This will help us to average and have an aggregated view of how the prompt is performing
9. We average the metrics for all questions and answers and print the metrics.
By just applying mean to each of the metrics, we can get some high level overview on how the prompt template is performing on average.
evaluator.print_evaluation(metrics, answers)
🎯Explicit: 75.0%
🎯Helpfulness: 100%
🎯Directness: 100%
🎯Grammaticality: 100%
🎯Relevance: 100%
🎯Edge: 0%
🎯Factuality: 100%
🎯Supposition: 75.0%
🎯Objectivity: 100%
🎯Creativity: 0%
🎯ThirdPartyOpinion: 0%
🎯Source: 75.0%
10. Additionally, you can apply other non-LLM-based metrics as ROUGE and BLEU
As stated before, ROUGE and BLEU can be used as additional metrics for your evaluation process. Although they can’t be used by themselves to completely assess the issues of the prompt, they reflect the level of informativeness and similarity of the answer compared to the knowledge.
!pip install rouge==1.0.1
!pip install bleu==0.3
import rouge
def evaluate_rouge(answer, knowledge):
rouge = Rouge()
scores = rouge.get_scores(answer, knowledge)
return scores[0]
🟥ROUGE: 0.10
from bleu import list_bleu
def calculate_bleu_score(question, answer):
question_tokens = question.split()
answer_tokens = answer.split()
return list_bleu([question_tokens], answer_tokens)
🟦BLEU: 0.10
11. Every time a metric fails for a question, we print it and take a correcting action.
As you may have observed, we got a 75% in the 🎯Supposition metric. Which means our prompt did not properly work for some of our questions, as for the A fish is capable of thinking?.
It seems the answer A the Language Model provided for a question Q and the knowledge K in the Vector Store can’t be properly inferred from Q and K, supposing a risk to our inference process. This is what our 🎯Supposition rule is all about.
❌Failed 🎯Supposition Rule for question `A fish is capable of thinking.`
- 📜 Fish are more intelligent than they appear. In many areas, such as memory, their cognitive powers match or exceed those of ’higher’ vertebrates including non-human primates. Fish’s long-term memories help them keep track of complex social relationships.
- - 🤔 Yes, based on the provided knowledge, a fish is capable of thinking. Fish have cognitive powers that match or exceed those of “higher” vertebrates, including non-human primates. They have long-term memories that help them keep track of complex social relationships. Therefore, it can be inferred that fish are capable of thinking.
And indeed, the LLM answer says explicitly Yes, which is a supposition the model did. It is nowhere in the knowledge provided that fish are capable of thinking. They say they are more intelligent than they appear, which led the LLM to that conclusion. But that’s a supposition, not a factual answer**.**
12. We apply correcting actions to the prompt.
It seems our model (as usually happens), can make decisions, infer conclusions based on its logical inference (not always matching human reasoning capabilities), make suppositions and bad conclusions.
Our failed 🎯Supposition rule now will trigger a correcting action on the prompt to prevent this to happen in the future.
How we can achive that? As mentioned before, there are three ways you can do it using:
- A rule-based approach, where for each metric you create, you also generate a description to be added to the prompt of you to fix it.
- A deep-learning approach, where you train a machine translation model, able to transform text X into text Y, being Y an optimized version of X given the fails.
- LLMs. You can create a prompt to ask, for example, OpenAI to optimize the prompt for you given a series of failed metrics.
If you want more information about any of those three approches or you are more interested in the prompt for 3), reach out to us at hi@mantisnlp.com
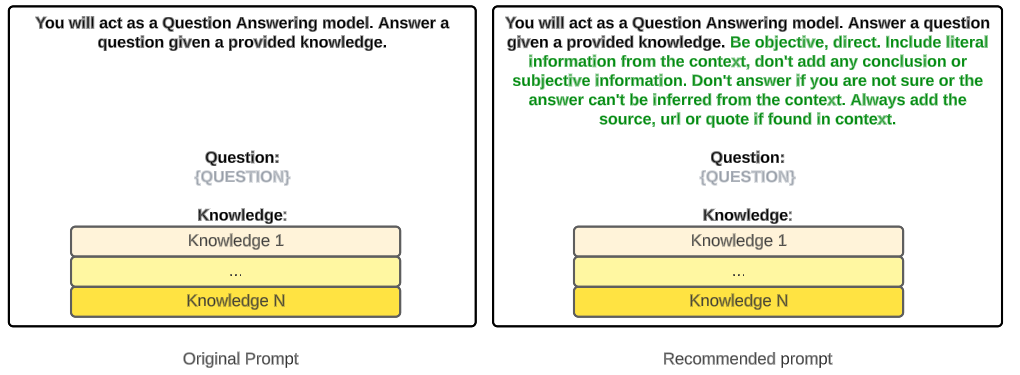
Before:
You will act as a Question Answering model. Answer a question given the provided knowledge.
Question: {question}
Knowledge:{knowledge}
After:
You will act as a Question Answering model. Answer a question given the provided knowledge. Don’t make suppositions, conclusions or infer any logical consequence based on your thoughts. Just answer the question if it clearly states the answer in the knowledge.
Question: {question}
Knowledge:{knowledge}
Alright! Those were the 12 steps we took from Knowledge Retrieval to Knowledge Integration, generation of answers and evaluation. Now, one last question remains — how can we do it in an optimal way, reducing the costs, reusing as much as possible and feedbacking the process?
Reusing the feedback with templates to scale and reduce costs
The main concern you may have at this point is the cost of the subsequent calls to the NLP API for each prompt. Don’t worry, we’ve got you covered!
Of course, any evaluation of prompt means using LLMs several times: for resampling and also for getting the answer for each sample. That’s a lot of calls and a lot of money per question!
However, as we have showcased, and also as stated in the Large Language Models are human-level Prompt Engineeringspaper, you need to use prompt templates, which can be generic for any question, but which incorporate a series of instructions you can improve by automatic prompt engineering, as we did in the point before. Then, the question will be integrated in the prompt as shows the following figure:
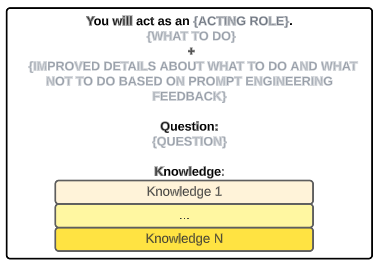
By running it several times, it can result in a very robust template which can be reused in time with any different kind of question you may have. As we mentioned those suggestions can come either from a rule-based approach, or a Deep Learning model (discarding checking again with the LLM since this may incur more costs).
Conclusions: Better than a human annotator?
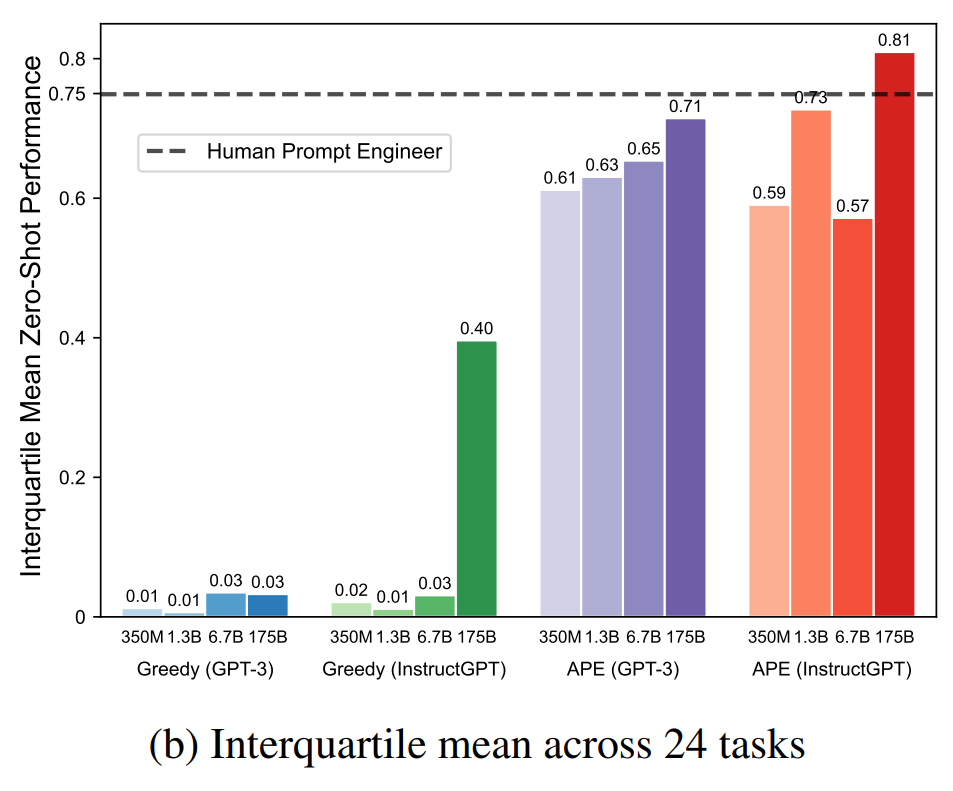
The Large Language Models are human-level Prompt Engineeringspaper concludes that by applying Automatic Prompt Engineering, you can increase in 6 percentual points the performance of your queries compared to a Human Annotator.
This will also result in:
- Reduced hallucinations
- More accurate, objective prompts
- Less false positives
Want to know more?
I hope you enjoyed this series of 4 posts and it is now clearer how to optimize your prompts to reduce hallucinations when using prompts. If you need to review any of them, please do! Here are the links: Part I, Part II, Part III and Part IV (this post).
As a conclusion — It is totally feasible, with not many lines of code, to build your own Prompt Evaluation and Automatic Prompt Engineering system. Then, you can go as deep as you want taking the inspiration of this blog posts, the papers mentioned in the series and the other resources we have shared with you.
If you need help with such a problem or you want us to take care of it, feel free to reach out at hi@mantisnlp.com.

Automatic Prompt Engineering (Part IV: Hands-on: Evaluation) was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.