
Constructing a knowledge base with spaCy and spacy-llm
Categories:
Overview
Extracting a knowledge base from a corpus has been a slow process until now, but no more. In this blog post, we are going to explore how the recent advancements in Natural Language Processing (NLP) help, and how they offer a new tool to tackle this complex problem. We will end up using a custom LLM approach to extract relations between important entities from text.
Let’s start by explaining the different concepts and tools we are going to be touching on.
What is a knowledge base
A knowledge base (KB) is a centralized repository for information, stored in a structured way, used by both computer systems and humans. It contains related information about a particular subject and it can be used in multiple ways:
- To organize data in a clear structure for easy search
- To infer new information based on the existing connections
- To better visualize all the connections between entities
The main difference between a normal database and a KB is the fact that unlike a normal database that may store individual and unrelated pieces of information, a knowledge base is typically structured in a way that reflects relationships between its pieces of content.
A KB is built around an ontology. An ontology defines what type of entities and relationships exist in the knowledge base. For example, an ontology might define a “Computer” as an entity, then describe its relationships (like “has-part” CPU or “uses” Software) and attributes (like processing speed or storage capacity).
The underlying structure for representing a knowledge base therefore is a graph, with the nodes being the entities of the KB, and the edges being the relationships between them.

Dall-E 3’s go at a knowledge base in the form of a graph
Knowledge base extraction
We’ve established that a KB is a very clear and structured way of representing information. Constructing such a knowledge base manually though is very expensive and time consuming. That is why there is heavy focus on automatically extracting the information using a series of steps.
The extraction process typically involves the following steps:
- Information retrieval — this involves searching and collecting large amounts of unstructured data relevant to the domain of interest
- Named Entity Recognition (NER) — Identifying and classifying named entities in the text like person names, organizations, locations, etc.
- Co-reference Resolution — This involves identifying which mentions in the text refer to the same entity.
- Relationship Extraction (RE) — Once entities are recognized, the next step is to identify the relationships between them.
- Ontology mapping — The extracted information is often mapped to an existing ontology or schema.
- Populating the KB — The validated and structured information is then added to the knowledge base, often a knowledge graph or a database.
Entity recognition and relationship extraction are 2 of the essential steps in knowledge base extraction. Both tasks require a profound grasp of context and linguistic intricacies, making them pivotal hurdles in knowledge extraction. We will focus on these 2 as they are the core components.
Up until recently, entity recognition and relationship extraction were time-consuming and costly steps, often taking months. This is because one had to go through the process of finding pretrained models, if they existed, and fine-tuning them or training models from scratch. In both cases this meant spending a lot of time on data annotation and developing the models.
In the last few years though, we have had this incredible surge and advancement because of Large Language Models (LLMs). LLMs can perform many NLP tasks out of the box, but often lack performance when compared to smaller specialized models. This makes them a very good choice for prototyping a solution, especially when a smaller specialized model does not exist.
A very common tool for these tasks is spaCy, an open-source NLP library renowned for its speed and efficiency. Additionally, spaCy has a long list of state of the art specialized models in most languages and furthermore, you can now use LLMs in spaCy as well, which can be very powerful bringing together the best of both worlds.
Constructing the knowledge base
We are going to show how you can use a combination of a spaCy specialized model (to extract entities) and a Large Language Model (LLM) through spacy-llm (to extract relationships) to extract a knowledge-base graph from a corpus of data.
Let’s set the stage by discussing what dataset we are going to use, and what entities and relationships we plan to extract from it. We will be using a news dataset, the aim being to extract information about people, places, events and companies (and their relationships). The dataset is in English, as are the models we’ll be using.
Thanks to spaCy’s pretrained NER models, we have the extraction part solved for these type of entities. The LLM will come in handy to extract the relationships between the entities. This is where that prototyping power that we were talking about comes in, because we can define pretty much any relationship we want to extract and lean on the LLM to do it.
In terms of relationships, we’ve selected a few that we want to focus on to demo what can be done:

The extracted information will be a simple list of tuples (subject, relation, object) saved in a csv, so that it can then be parsed by whatever graph library you see fit.
Every step we will be doing will be added to a spaCy pipeline.
Sidenote: The spacy-llm version that was used here is 0.6.2, 1.0.0 is in the works and it’s supposed to offer more features and more stability.
Extracting the entities
Extracting the entities in this case is very easy as all the entity types we decided upon are part of the pretrained spaCy NER model. As such we can use the spaCy “en_core_web_md” model.
For more complex cases though, you could use an LLM to detect the entities instead. Fortunately spacy-llm has that covered as well with its NER task. We will just need to configure it by specifying what labels we want to be extracted.
This is how the configuration for using the spaCy pretrained model looks like:

Extracting relationships
There are very few pretrained models for relationship extraction. That is why LLMs are such a great prototyping solution, because we can use them instead to get a base for our relationship extraction. Again, spacy-llm has that covered with the REL task, our job is to describe the relationships we want extracted.
This is how we configure the REL task, by specifying the predefined task, the labels (relations) and the LLM model we want to use.
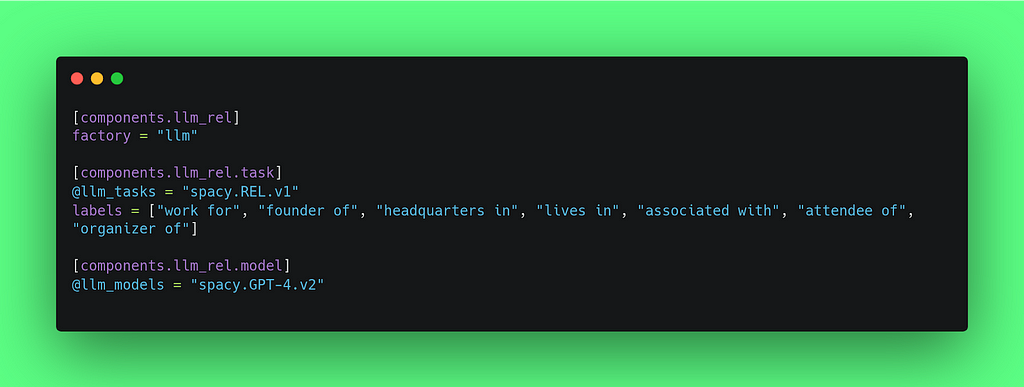
Creating our pipeline
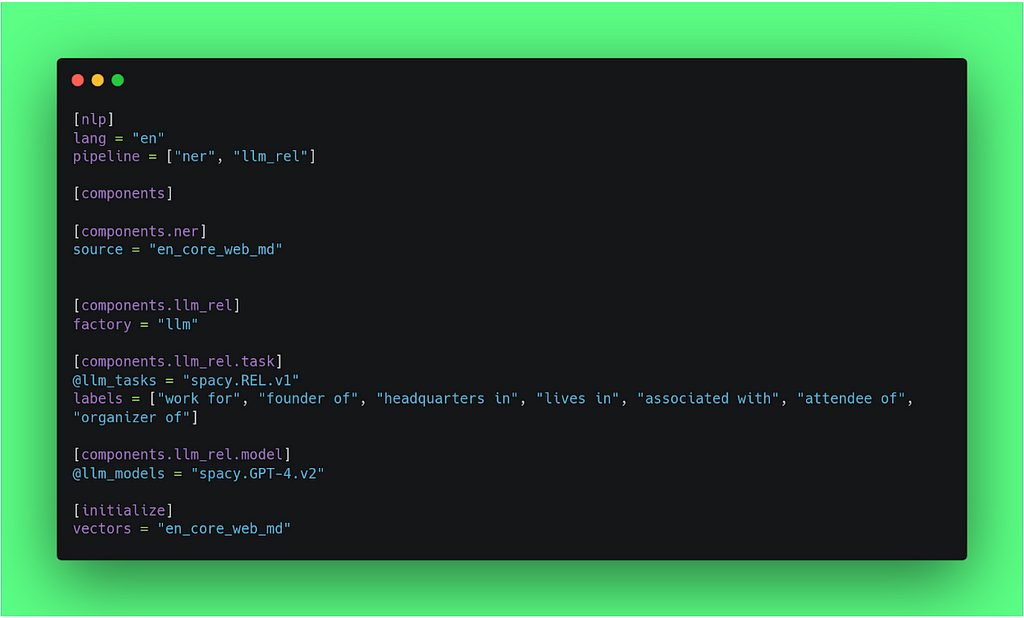
We can define our pipeline’s configuration in a .cfg file. Here is the place where we specify what NER model to use and what labels to extract, and the same goes for the relationship extraction task.
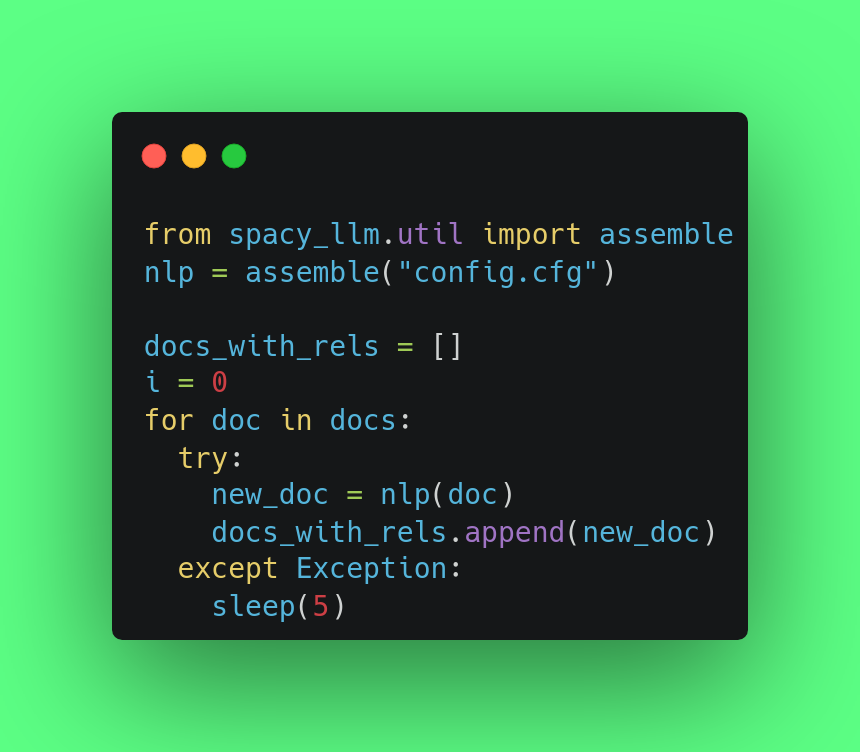
We then load the configuration and parse each document. (The except is there to handle OpenAI’s sometimes failing calls because of rate issues)
We now have a list of tuples that we can save and transform into a graph. To visualize the results, we’ve chosen the pyvis library, which allows the creation of interactive network visualizations.
This is how we construct the graph and generate the visualization you see below:
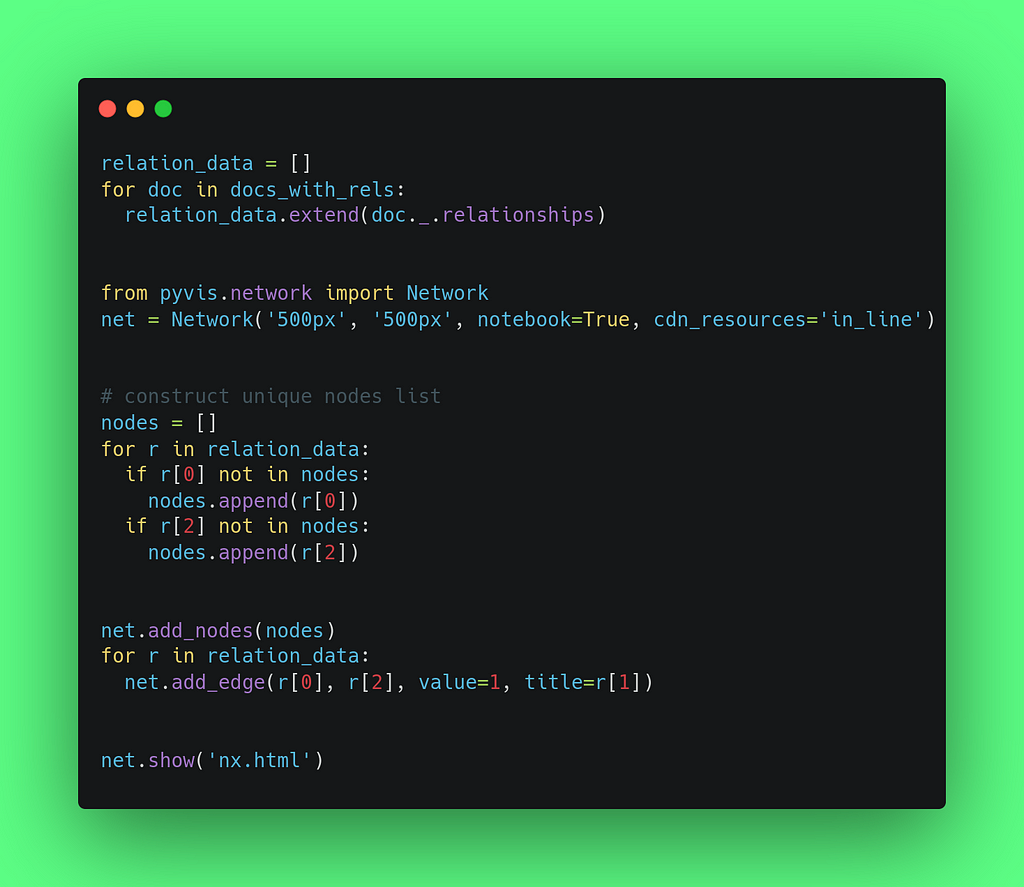

Go to this git page to interact with the graph
Custom task alternative
We already saw that you can get a lot of power just by using the predefined tasks from spacy-llm. But what if you have a more complex case in which for example entities aren’t as standard? You can still use spacy-llm and even have an LLM do the entity extraction plus relationship extraction in one go. We will define our own custom task to illustrate how that would be done.
First, let’s define our custom task. To do that we need to register it, and define the `generate_prompts` and `parse_responses` functions. Below you see we do that and we define the prompt for the LLM.
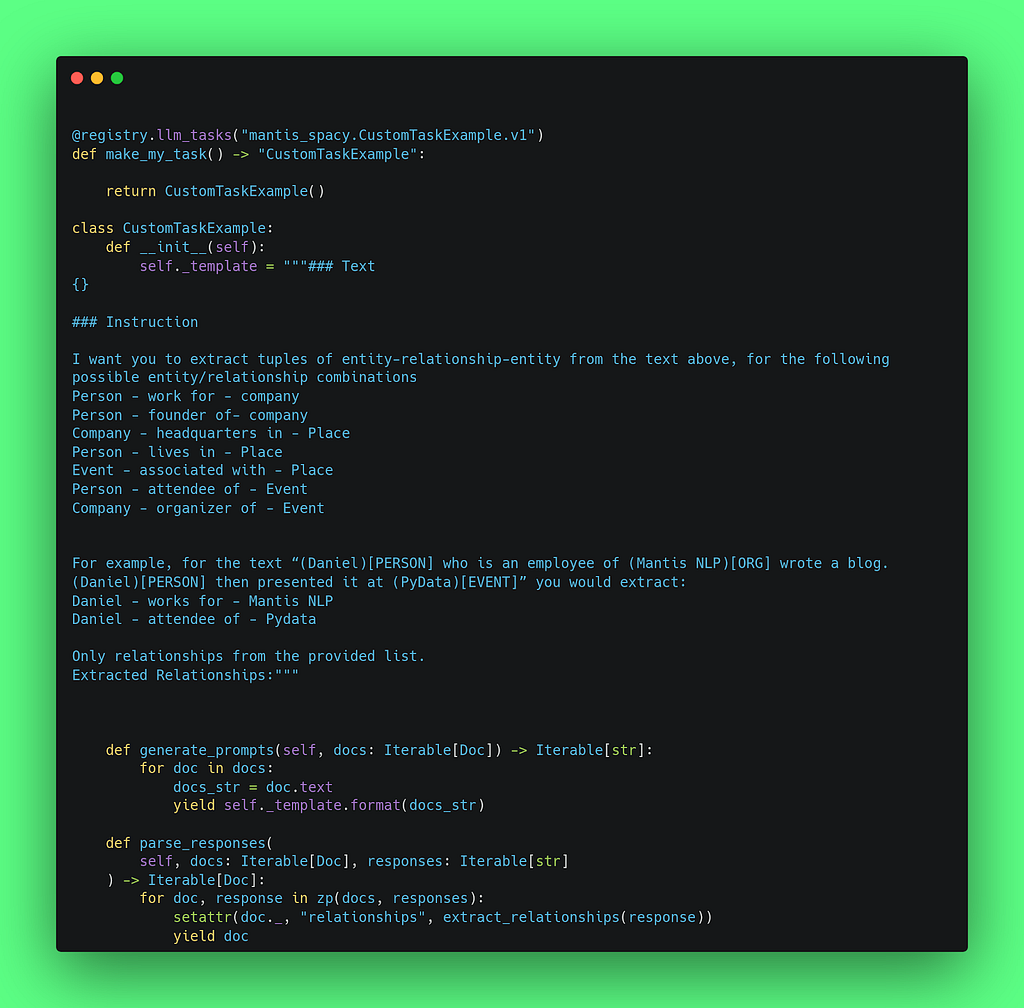
The config would then be a bit simpler as both NER and RE are done in our custom task by one LLM call:
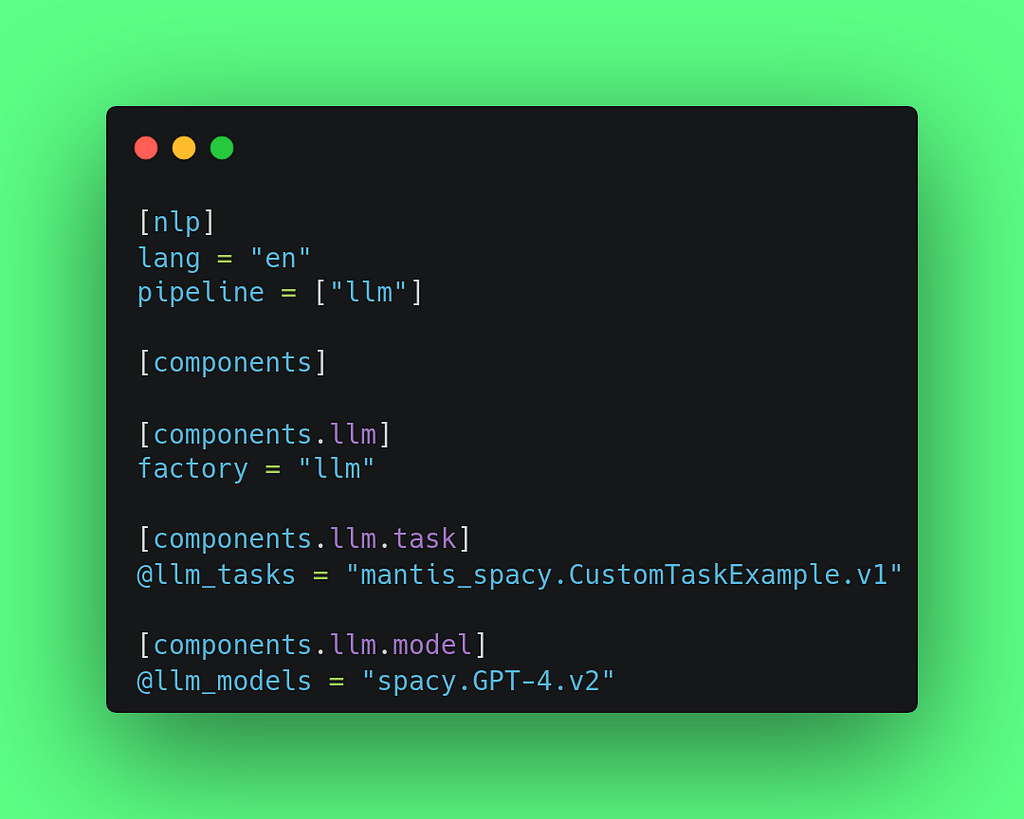
This example is mainly to show how you can handle complex situations using spaCy and spacy-llm. The benefit here is that it lets you combine this with other spaCy or spacy-llm tools, making it easy to set up a well-rounded and effective workflow.
Conclusion
We’ve seen how we can easily define our own relationships and use an LLM to extract them. The power of the LLM means we get good results, but it can come at a cost. Especially since we usually need to parse huge amounts of data to construct a knowledge base. Fortunately, this can be viewed as the first step in a bigger pipeline.
The data generated by an LLM can be used as a foundation for training a smaller model targeted specifically at extracting our specific relationships. For that, we need to set up an annotation step and a training step, which will be exactly what our next blog in the series is about.
Constructing a knowledge base with spaCy and spacy-llm was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.