Deploy a cutting edge machine learning model with one line of code
Categories:
I recently posted about why we have been switching some of our Machine Learning (ML) models to run inference Hugging Face Inference Endpoints. In that blog post I made reference to hugie which makes deploying models to Inference Endpoints really simple. In this post I’m going to introduce hugie, and what it can do.
Spoiler: it lets you deploy an Inference Endpoint in one line of code:
What is hugie?
Hugie is a small, Python based command line interface (CLI) for managing Inference Endpoints via the API. We started using Inference Endpoints to support a production use case, and we needed an easy way to deploy Inference Endpoints as part of our CI/CD pipeline powered by GitHub Actions.
How do I pronounce it?
Huggy, like a hug but a bit more? From Hugging Face Inference Endpoints. With a little reference to Huggy Bear Brown.
How do I get it?
You can install hugie directly with pip:
pip install hugie
How do I create an endpoint?
1. Export your Hugging Face API token into an environment variable called HUGGINGFACE_READ_TOKEN, e.g.:
export HUGGINGFACE_READ_TOKEN=api_XXXXXXXX
2. Define a config file for the endpoint you want to create. For this we can just download one for a small translation model with:
curl -O https://raw.githubusercontent.com/MantisAI/hugie/main/examples/development.json
This config contains information about the model to be deployed, the size of the instance to deploy it on, the region, replicas, etc. We’ll look at the config in more detail later.
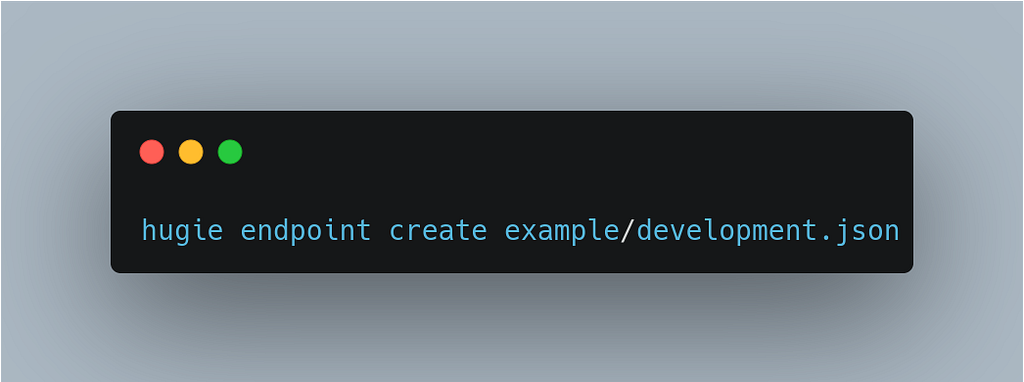
3. Create the endpoint:
$ hugie endpoint create development.json
Endpoint development created successfully on aws using t5-small
How do I check the endpoint status?
We can check the status of all of our endpoints with the endpoint list command:
$ hugie endpoint list
> > > Name State Model Revision Url
---
development initializing t5-small main None
Once the endpoint is deployed, the URL field will be populated, it will look something like this:
https://abcdefghijklmnop.us-east-1.aws.endpoints.huggingface.cloud
We can also use the watch command to keep a constant watch on what endpoints we have running with:
$ watch hugie endpoint list
How do I query the endpoint?
If you want to test that the endpoint works, you can use the endpoint test command:
$ hugie endpoint test development “This is a test”
> > > [{‘translation_text’: ‘Dies ist ein Test’}]
Notice that we pass the instance name (defined in the config) and a string that we want to do inference on. You can also pass a path to a JSON file containing multiple queries with the — input-file option.
For production use cases, we query the API using an HTTP POST request. We need to pass a Bearer token for authentication. Here’s how to do it using curl:
curl https://abcdefghijklmnop.us-east-1.aws.endpoints.huggingface.cloud \
-X POST -d ‘{“inputs”: “This is a test”}’ \
-H “Authorization: Bearer ${HUGGINGFACE_READ_TOKEN}” \
-H “Content-Type: application/json”
> > > [{“translation_text”:”Dies ist ein Test”}]
Cool, so what’s in the config file?
The config files lets you set parameters such as the cloud vendor you want to use, the region where the endpoint will be deployed, the size of the endpoint, etc. In our example we create a small endpoint in the AWS us-east-1 region running a translation model t5-small. It’s default behavior is to translate texts from English into German:
{
"accountId": null,
"compute": {
"accelerator": "cpu",
"instanceSize": "small",
"instanceType": "c6i",
"scaling": {
"maxReplica": 1,
"minReplica": 1
}
},
"model": {
"framework": "custom",
"image": {
"huggingface": {}
},
"repository": "t5-small",
"revision": "main",
"task": "translation"
},
"name": "development",
"provider": {
"region": "us-east-1",
"vendor": "aws"
},
"type": "protected"
}
You can read more about the config settings in the Inference Endpoint docs.
What’s coming next?
- Tighter integration with the Hugging Face Inference Endpoints API so that you have access to all the functionality of the API.
- A more streamlined flow to allow you to create endpoints on the fly, and some functionality around setting things like provider, and type defaults, to reduce the amount of work you need to do to deploy an endpoint.
👋Get in touch!
Hugie is an open source project. We welcome your contributions in comments, issues, and PRs! And if you want help with deploying transformers into production where you work, get in touch with us at hi@mantisnlp.com, or drop us a line.
Deploy a cutting edge machine learning model with one line of code was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.