
Digitizing Unstructured Accounting Data with LLMs
Categories:

Dealing with unstructured accounting data can be a nightmare, especially when it comes in the form of messy PDF files. While this issue is less common today as most workflows rely on machine-readable formats, it can still arise in scenarios where such formats are unavailable or unsupported by outdated software. We faced this challenge in the process of digitizing several pages of internal accounting data that were originally presented in poorly structured tables in PDF format, making them hard to interpret and analyze.
The goal was to extract and organize this data efficiently, creating a digitized, error-free dataset. We used Large Language Models (LLMs) as a tool to enable this extraction with robust performance. This blog post is an explanation of the approach we followed, the methods we tried, and what worked best to achieve good performance.
Initial Approach: Using LLMs directly on the PDF files
The data consisted of accounting entries reported across multiple PDF files. These PDFs contained tables with an unstructured format and an inconsistent layout, which made it difficult to extract the information directly. For example, some entries spanned multiple lines, there was inconsistent use of separators. The variation in between tables was large, making it complicated to build a rule-based parser. In short, the data was messy and very challenging for any conventional extraction tool or standard parsing strategy to efficiently perform the task.

Example of Accounting Entry
To tackle this, the first attempt was to use the OpenAI GPT-4o API to extract the data directly from the PDFs providing them as an attachment to the prompt. The information regarding the parsing strategies in the backend used by OpenAI on PDFs is not fully available, but probably combines programmatic markdown text extraction with some vision capabilities. The first step in this process involved some prompt engineering and few-shot learning to ensure the model had all the necessary information, a good understanding of the instructions and the requested output format.
We used the following prompt:
prompt = """
Task:
Extract detailed financial transaction data from a multi-page PDF document into a structured JSON format.
Context:
The file contains a page with different types of financial transactions.
Output Format:
Provide the output as a JSON array, where each object represents a single entry. Output the data as a single JSON array. Do not provide any explanations or code.
Output Example:
Expected Output Example:
[
{
“Page”: “1”,
“Page Description”: “Lorem ipsum dolor”,
“Line”: “1”,
…
}
…
]
"""
Specific and complete examples were provided in the original prompt’s “Output example” section. After some iteration to ensure a well-defined prompt, the next step consisted in the creation of a script uploading each PDF file page singularly in a loop and prompting the LLM to parse the content of the page into structured JSON objects.
However, this approach quickly revealed its limitations. Accounting data is highly sensitive and demands absolute accuracy, on top of that, once errors occur, they can be very hard to detect. Mistakes in this type of data can lead to significant issues in reporting, so the parsing strategy had to be as robust as possible to prevent them. Since LLMs are susceptible to hallucination, a manual review of the extracted data would still be necessary to guarantee complete accuracy. However, if the data is extracted correctly enough, the manual review will definitely be faster, reducing costs of the process.
Providing the LLM with the PDF files as an attachment, errors in the extracted data were numerous and seemed to not get fixed solely with prompt engineering. The LLM struggled to capture the different lines, messing up rows or column names, or even worse: the model was prone to hallucinations in the numerical amounts causing serious reporting issues. The results obtained using this technique were not sufficiently going to help the reporting, instead might have been complicating it.
Extracting Data from Screenshots and Parsing the Output
Realizing the limitations of the initial approach, we tried something different: instead of using the raw PDFs, we provided screenshots of each PDF file page to the LLM with the same prompt and the same instructions. By converting these PDFs to PNGs, the LLM parsing ability improved significantly using solely image-based data extraction. The model was more effective at understanding and structuring the data when it was extracted directly from screenshots (PNGs) rather than from the internally preprocessed PDF files.
The improved extraction accuracy allowed a more reliable conversion of the data into JSON objects for each file, which could then be aggregated into a CSV for a clean, organised view of the entries.
To increase robustness, after data extraction, a new parsing layer was added to the pipeline. Following some observation of recurring mistakes in the extraction of the data, this script was introduced to correct and track all the possible mistakes in the LLM output. The CSV file of the combined output obtained from the previous steps in the pipeline was analysed applying some predefined rules. Examples of the rules included checking if debits and credits are matching, checking if VAT amounts are correct based on the corresponding exchange rate, or checking if every entry is being reported in full. This additional step in the pipeline enabled the correction of some common mistakes and the reporting of all of the changes or potential mistakes in the PDF parsing.
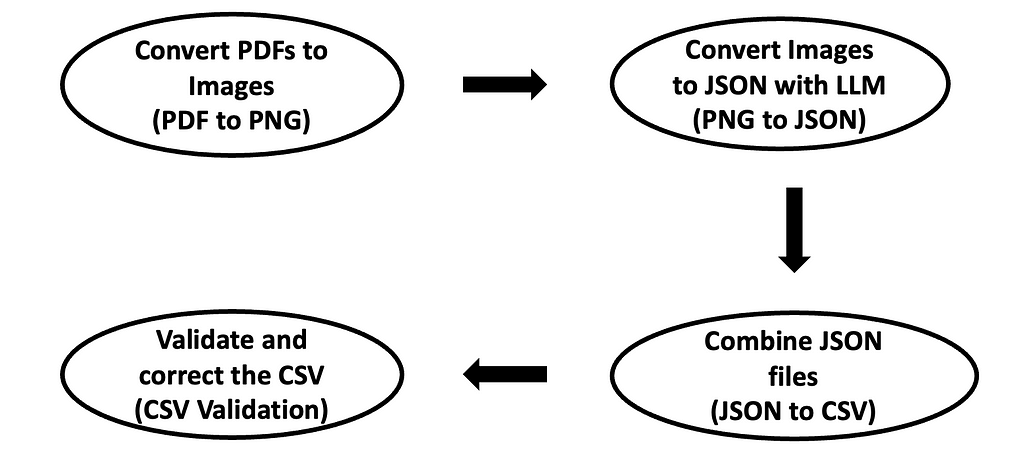
Workflow of the Program
Results and Takeaways
The approach involving a pipeline in which the PDFs were converted to images before being fed to the LLM and then the output parsed and checked, helped to retrieve cleaner accounting data ready for manual annotation. The LLMs could better handle the data inconsistencies and produce more accurate JSON outputs. This allowed us to create a comprehensive CSV file that combined all the entries into a structured format.
LLMs are still not reliable enough to handle delicate tasks such as dealing with accounting entries. However, from this project we deduced the importance of adapting the extraction method to the specific characteristics of the data. When working with unstructured data in PDF files, using a pipeline including image based data extraction can dramatically improve accuracy.
Conclusion
This project highlighted the power of LLMs in dealing with complex data extraction tasks, but also underscored the need for flexibility, experimentation in choosing the right approach and enhanced robustness using different techniques. If you’ve faced similar challenges or have suggestions for further improvements, feel free to share your thoughts!
Digitizing Unstructured Accounting Data with LLMs was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.
