Eight examples is all you need ✨
Categories:
It is no secret that the power of machine learning models comes from the data that they are trained on. It should come as no surprise then that the most common question we get at the start of any project we take here at Mantis is “How much data is needed?”. Since more often than not the data would need to be prepared specifically for the task at hand, there is a tradeoff between the cost of data collection and the performance you get back.
The good news is that we have been making progress in the amount of data required to reach a certain level of performance. Up until recently a good rule of thumb has been to have at least 100 examples per class in a classification problem. A classification problem would be, for example, to identify spam vs no spam emails. Then, transfer learning and pretrained models arrived which I would say halved that requirement to about 50 examples per class. The ability of those models to learn more efficiently came from pre-training them in large amounts of text or image data which allowed them to learn useful information that they can “transfer” to the task at hand.
Unlike more traditional approaches, those pretrained models, in particular transformers, seemed to scale well with more data so it was natural to ask whether larger models would reduce the amount of data needed even further. As we have seen with GPT3, and ChatGPT more recently, the answer seems to be yes. These models seem to be able to perform almost any task with few to no data. These large language models (LLM) came with two main caveats
- They were extremely large, and as a result expensive to use routinely compared to smaller pretrained models
- They were quite sensitive to “prompting” which is the “instructions” you gave them at the start to perform a task. We have written an entire blog post series if you are more interested in this topic.
Even though prompting seems to be on the way out as a problem, as we have seen with the recent work in alignment which have resulted in InstructGPT and ChatGPT, the size and cost of LLMs is still a problem. This is where SetFit comes in. SetFit is a recent modeling approach that builds on top of pre-trained models and a technique called contrastive learning. The important thing is that it enables smaller pretrained models to perform well after training with as few as 8 examples per class with neither a prompt nor the size of the large models. Let’s see a performance comparison straight from the paper that introduced the technique.
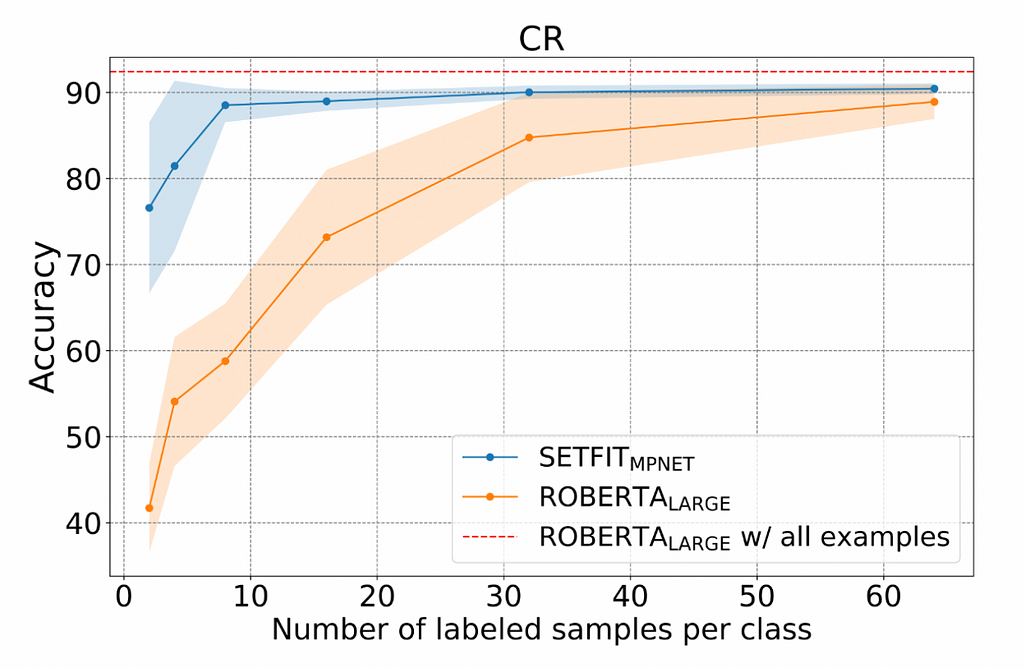
The above graph compares SetFit using Mpnet with Roberta large, a standard baseline choice for pre-trained models. As we can see, it takes only 8 examples per class to reach the same performance that Roberta requires close to 64. We also see that the point of diminishing returns is 8 examples per class. At that point we get much less than a percentage point every time we double the data. The model performs very close to a model trained with all examples in that dataset indicated by the dotted red line. Let’s see a similar graph I produced on two additional datasets

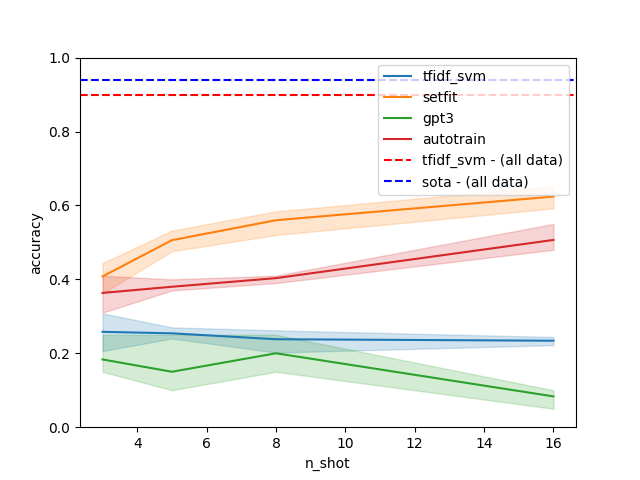
In the above graph we compare SetFit with AutoTrain which is an AutoML solution from huggingface 🤗as well as GPT3 and Tf Idf SVM, a more traditional model. The left graph is on the ag_news datasets while the right is on emotion. SetFit seems to easily outperform the other models in regards to how much data it needs for a given performance and 8 examples still seems to be the point of diminishing returns. At the same time, GPT3 performs quite poorly but this might be related to the prompt choice.
There are definitely some caveats with SetFit. For one, as we see on the right-hand graph, it does not always perform as close to the state of the art performance with few examples. This might be related with the choice of pre-trained model but even so it’s worth keeping in mind that using SetFit with 8 examples per class is not a silver bullet. Even more importantly, SetFit only works in text classification tasks, so there are a number of Natural Language Processing applications it will not be relevant to, like extracting mentions from documents or generating text. Those caveats aside, the trend of needing fewer examples per class to get a working model going is one that is here to stay.
How does SetFit do it? 🤔
As we said previously, SetFit builds on top of pre-trained models and a technique called contrastive learning. Typically contrastive learning is used to learn better features or embeddings for text or images. This is very relevant in applications such as similarity search where you want to produce representations that are closer in space for similar items. To train a model using contrastive learning you need pairs of items that are similar i.e. positive and dissimilar i.e. negative. The main trick behind SetFit is that a text classification dataset can be turned into pairs of positive and negative examples, which in this case would be pairs from the same class and pairs that belong to a different class. Here is the whole SetFit pipeline.
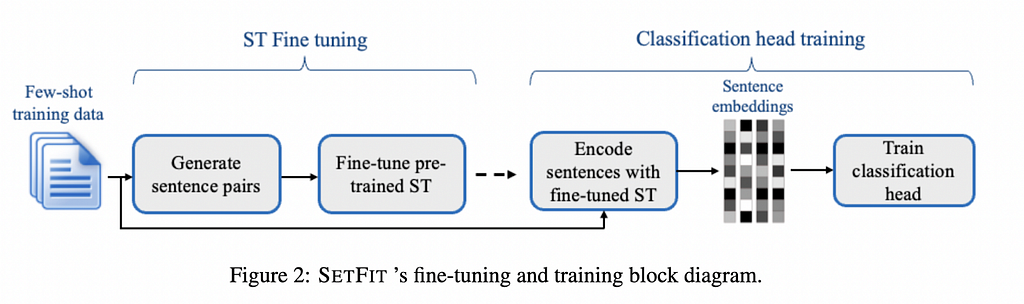
The first step of the pipeline is to generate sentence pairs from your training data similar to how we discussed. This process ends up producing many more examples than initially available because each training example can be combined with any other. As it turns out, there was more useful information inside a text classification dataset than traditional text classifications methods were making use of. That is the information that pairs of examples from different classes are dissimilar while examples from the same class are similar. Using contrastive learning, SetFit can make better use of this extra information, in this first step resulting in a pre-trained model that can give us better representations.
Having that model, the second step is rather simple. SetFit uses that model to embed the original text classification dataset and it uses a more traditional approach like SVM to classify the examples into classes.
So why not use a pre-trained model like Roberta to begin with to embed the data and add a linear head on top? Or at least why does that perform worse? Personally I think this is for two reasons
- We already knew from sentence transformers that pre-trained models do not produce the best representations for semantic similarity tasks and that contrastive learning instead was a much better objective to achieve that. On the other hand, this is not a semantic similarity task, which leads me to the next point
- Modeling the problem as text similarity and producing combinations of examples as similar and dissimilar examples as we show, can be regarded as a data augmentation technique. This multiplies the amount of data available and unsurprisingly leads to better representations.
SetFit might be mainly relevant to text classification but it is important for industry use cases to have more approaches that reduce the amount of data we need to get started with a problem. At Mantis we are actively following progress towards that direction since this directly impacts all our clients. We will certainly be writing more on this topic so keep an eye on our blog, and if you have a Natural Language Processing that we can help with or a question about this or any other post, do not hesitate to send me an email at nick@mantisnlp.com
Eight examples is all you need ✨ was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.