
Fine-tuning Large Language Models on a budget with DEITA
Categories:
Using DEITA to fine tune your own LLM with limited budget. This blog post first goes through the main concepts for a non technical audience (5 minutes read) and then deep dives into DEITA implementation.
Introduction
In the wake of GPT-3.5, launched in late 2022 by openAI, development of Large Language Models (LLMs) has soared in the AI industry. Indeed we saw a lot of proprietary models with the GPT-series of course, Claude from Anthropic or more recently Goole’s Gemini. On the other hand, the open-source community has provided a lot of new models such as Llama 3, WizardLM or Mistral mixture of experts.
In both scenarios, training your own LLM to fit your business case follows the same process. First, pre-training the model with billions of texts in an unsupervised way, meaning that it almost trained itself, with the objective of the model being to gain a fine statistical understanding of how humans write in different contexts. The second phase, instruction tuning, in contrast, aims to align the model outputs with desired responses to specific instructions or prompts. To reach such an objective, you need to carefully choose the instructions and answers you want your model to learn. Therefore in terms of human investment, the second step is much more expensive and crucial to hit the LLM output quality we’ve been used to in the last year and a half.
Context
The instruction tuning phase is one of the keys to chatGPT success. It generally, as explained in an openAI post, goes through three steps: applying supervised fine-tuning on a dataset of instruction/response pairs, scoring different responses of the model to the same prompt to align with human preferences and then a fine-tuning phase using previous scores to guide the training towards human preferences.

Data to fine-tune a model: on the left, questions. On the right, the expected answers
In short, aligning your LLM with business expectations requires instruction tuning, also called reinforcement learning with human feedback. Nevertheless, it is expensive because it requires manual human labeling of instructions and responses, as well as quality scores to align with human preferences.
Since we don’t all have the money or ethics to pay for this labeling, we would recommend open-source solutions.
In a previous blog post, we detailed some instruction/response pairs that you could use to align your model for generic use cases. Moreover, a lot of models such as WizardLM, Dolly or Alpaca released their dataset which is a great contribution to the open-source community consolidating knowledge and giving the possibility to leverage it. We could think about leveraging all existing resources to generate a meta dataset to learn from as generally the models are known to scale with dataset size. However, the bigger the dataset the more expensive your instruction-tuning. On the other hand, some research has shown that a data-centring approach, focusing on smaller datasets with higher data quality could yield better results. Regarding instruction tuning to fit your business case, this creates a clear tradeoff between allocating a high budget to tune on large amounts of data or finding a way to cherry-pick the best qualitative data before tuning.
Problem-Solving
Most companies cannot allocate many resources for instruction-tuning . Therefore we decided to investigate how to select qualitative data for instruction-tuning based on limited development budget. We found that Liu et al. tackle the issue of first defining good data and second identifying it to respect an initial budget to instruct-tune your LLM.
DEITA (Data-Efficient Instruction Tuning for Alignment) studies an automatic data selection process by first quantifying the data quality based on complexity, quality and diversity. And second, selecting across the best potential combination from an open-source dataset that would fit into the budget you allocate to tune your own LLM.
Approach
The strategy utilizes LLMs to replace human effort in time-intensive data quality tasks on instruction tuning datasets. DEITA introduces a way to measure data quality across three critical dimensions: complexity, quality and diversity. For the first two dimensions, they introduced an automatic way of assessing the data sample: EVOL COMPLEXITY to score each instruction complexity and EVOL QUALITY to assess the response quality depending on the instruction. Based on those evaluations, the authors propose an iterative method to secure diversity in the final instruction/pair dataset.
This approach has been successfully used to generate datasets from scratch, and stands as a competitor to proprietary models in text classification tasks. Another example is the implementation of the automatic prompt optimizer to get a better response from LLMs.
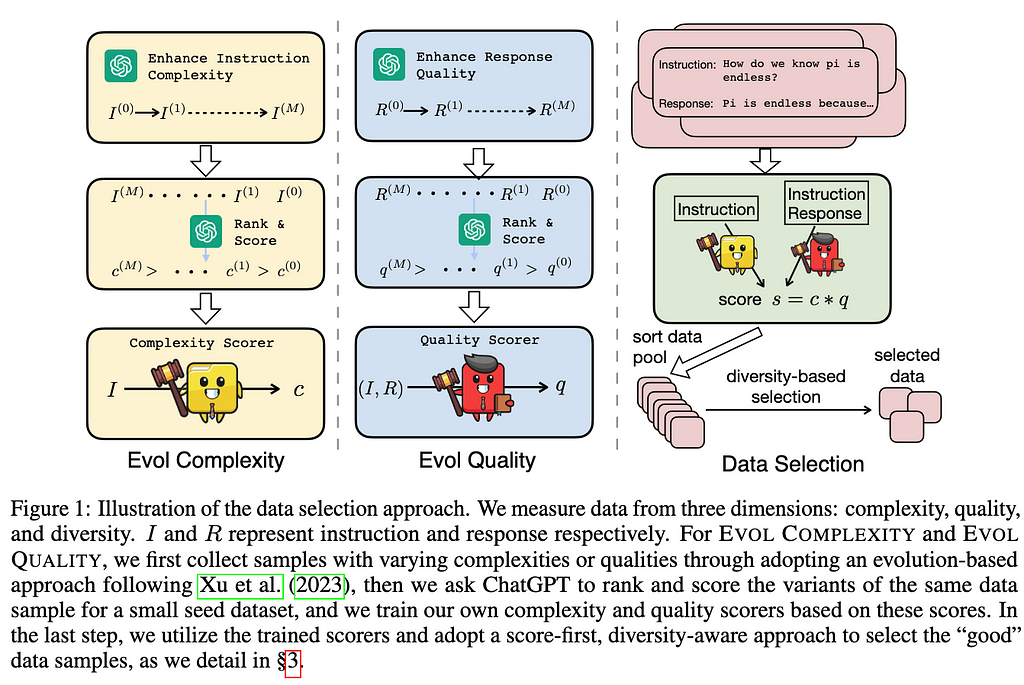
Credit: Lieu et al. (2023)
To fit within the budget constraint, they restricted their final selection to 6k instruction/response pairs. Upon refining this compact dataset, they proceeded to instruction-tune both LLaMa and Mistral models. This was done to benchmark against current methods and demonstrate the effectiveness of their technique.
Main contributions and results
The results are quite impressive: the DEITA approach selecting 6k performs better or on par with state-of-the-art open-source alignment models using over ten times less training data on different benchmarks (MT-bench, AlpacaEval and OpenLLM LeaderBoard).
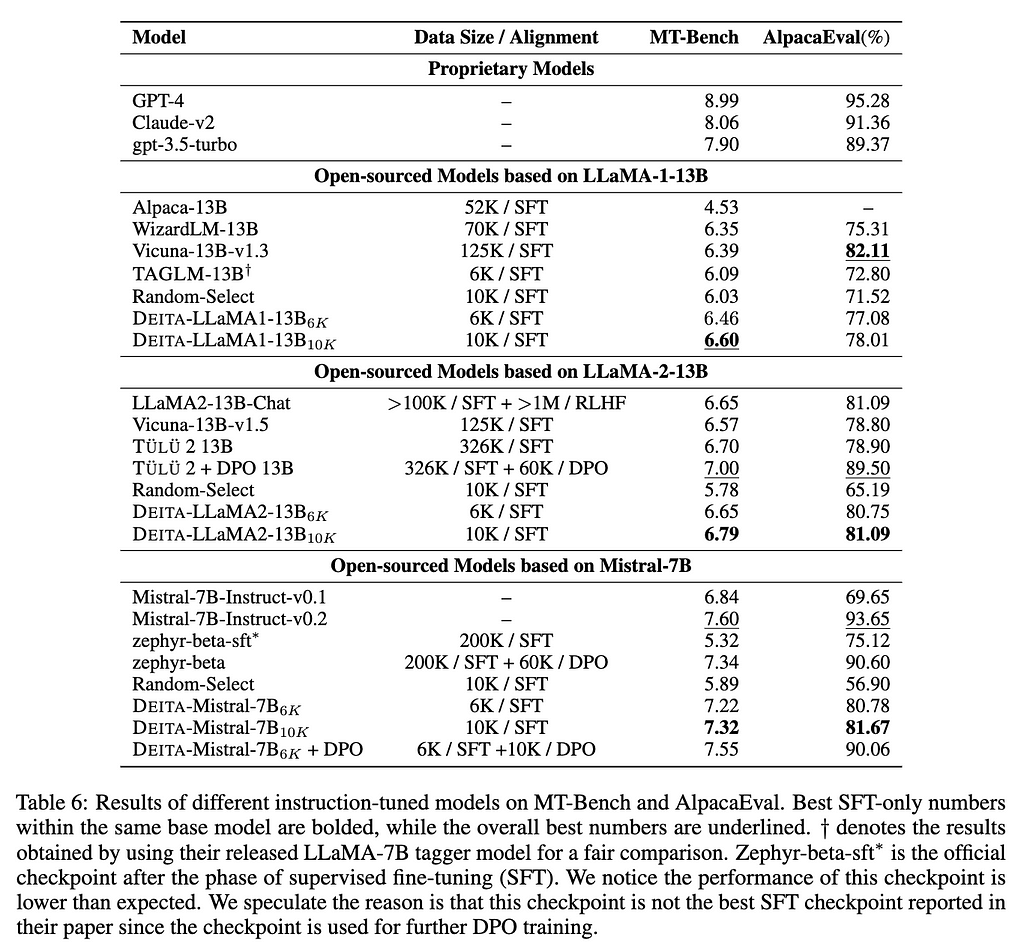
Credit: Lieu et al. (2023)
The strategy highlights that a data-centric approach is competitive with consolidating a larger meta-dataset from stacking open-sourced datasets together. Therefore, from a given budget, it’s preferable to select quality instruction-tuning data for an open-source LLM rather than cost intensive labeling. In turn, the higher quality dataset would lead to a trained model that performs at least on par with LLMs instruct-tuned with combined datasets, and ten times the budget.
Incorporating this approach alongside specific guidelines for automating the creation of instruction/response pairs could be a worthwhile exploration for those looking to train their own LLM tailored to their specific business case, especially when utilizing open-source models.
DEITA from the start
In the wake of the overview presentation of the DEITA paper, we will dive deeper into the whole process. We will investigate each stage to efficiently select the final dataset used for supervised fine-tuning with a budget constraint. We will tackle technical challenges by explaining exactly how you would assess good data as presented in the paper. Finally, we will take a step back to discuss some hypotheses the authors made. Our idea is to find some potential investigation path that could improve the approach.
As a reminder, we’re looking for a strategy to automatically select good data for the instruction-tuning step when you want to fine-tune an LLM to your own use case taking into account a resource constraint. This means that you cannot blindly train a model on any data you encounter on the internet.
Datasets and budget
The first big hypothesis the authors make is that you have access to open-source datasets that may fit your use case. Currently speaking it may not be the case, or at least totally aligned with your expectations. But with open-source communities soaring across the world, for instance, with projects such as BLOOM or AYA, we think that your use case should be tackled at some point. Or at least you will have the possibility to generate your own instruction/response pairs with methods such as self-generated instructions.
Therefore we will consider from now on that we have a data pool X_sota with enough data to work with and that actually we have too much data for our cost constraint. Then the main objective is to select a subsample of this data pool X_sota to fit our constraint. The main idea behind this sampling is, as the authors claim in the paper, that the subsample size “correlates proportionally with the computation consumed in instruction tuning”. Hence on a first approximation, reducing the sample size means reducing computation consumption and so the total development cost. Reproducing the paper notations, we will associate the budget m to a number of instruction/response pairs that you can set depending on your real budget.

Credit: Liu et al. (2023)
To match the experimental set-up, we can claim that the dataset X_sota is a meta-dataset combining all the open-source datasets used to instruct-tune LLMs with state-of-the-art results. In detail, this dataset is composed of ShareGPT (58k instruction/response pairs), UltraChat (105k instruction/response pairs) and WizardLM (143k instruction/response pairs). It sums to more than 300k instruction/response pairs. This makes a really interesting problem as we’d like to reduce the final subsample to 6k instruction/response pairs.
Complexity Evaluation
The second main step in the selection process to get good data is the evaluation of the complexity dimension for an instruction in a given instruction-response pair. To perform such analysis, the authors drew inspiration from Evol-Instruct introduced in the WizardLM. They call this method EVOL COMPLEXITY which leverages LLMs instead of humans to automatically score instructions. In the following steps we detail step by step how to use EVOL COMPLEXITY:

Credit: Lieu et al. (2023)
In-Depth Evolving Instructions
From any instruction-response pair, (I, R), we first automatically generate new instructions following the In-Depth Evolving Response. We generate more complex instructions through prompting, as explained by authors, by adding some constraints or reasoning steps.
Let’s take an example from GPT-4-LLM which aims to generate observations by GPT-4 to instruct-tune LLMs with supervised fine-tuning. And, we have the instruction instruction_0:
instruction_0 = “Give three tips for staying healthy.”
To make it more complex, you can use, as the authors did, some prompt templates to add constraints or deepen the instruction. They provided some prompts in the paper appendix. For instance, this one was used to add constraints:
PROMPT = """
I want you act as a Prompt Rewriter.
Your objective is to rewrite a given prompt into a more complex version to
make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.
But the rewritten prompt must be reasonable and must be understood and
responded by humans.
Your rewriting cannot omit the non-text parts such as the table and code in
#Given Prompt#:. Also, please do not omit the input in #Given Prompt#.
You SHOULD complicate the given prompt using the following method:
Please add one more constraints/requirements into #Given Prompt#
You should try your best not to make the #Rewritten Prompt# become verbose,
#Rewritten Prompt# can only add 10 to 20 words into #Given Prompt#
‘#Given Prompt#’, ‘#Rewritten Prompt#’, ‘given prompt’ and ‘rewritten prompt’
are not allowed to appear in #Rewritten Prompt#
#Given Prompt#:
#Rewritten Prompt#:
"""
Prompting this to an LLM, you automatically get a more complex instruction, called instruction_1, from an initial instruction instruction_0:
instruction_1 = “Provide three recommendations for maintaining well-being, ensuring one focuses on mental health.”
And now we can iterate through this path taking as input this first evolved instruction to be rewritten. You can use different prompts to deepen or increase the reasoning steps of your instructions. In the paper, they make 4 more iterations to get 5 evolved instructions (I0,I1, I2, I3, I4, I5 ) which makes 6 different instructions at the end of this step!
Rank and Score Complexity
Once we get those sequences of evolved instructions, we again use LLMs to automatically rank and score them. But in this task, there is a crucial point: when asking an ad-hoc LLM to score the 6 instructions, we need to provide the 6 instructions at the same time!Indeed, if we were asking someone or an LLM to score independently each of the instructions, it’s most likely that the scorer will not necessarily discriminate the complexity of all prompts and it could lead to the same score for each instruction. By providing all instructions together, we force the scorer to look at slight complexity differences between evolved instructions. Therefore the LLM most likely discriminates better between instructions. For instance, scoring instruction_0 and instruction_1 independently could lead to sensibly the same score in the end, but if we take it together we would notice the slight difference that makes instruction_1 a bit more complex.
instruction_0 = “Give three tips for staying healthy.“instruction_1 = “Provide three recommendations for maintaining well-being, ensuring one focuses on mental health.”
To score together the instructions you can use a prompt similar to the one the authors used:
PROMPT = "””
Ranking the following questions according to the difficulty and complexity.
Score 1–5.
You can give a score of 6 if the question is too complex for you to answer it.
You should respond with the format:\n [1] Score: 1\n [2] Score: 2\n
[1] <Instruction 1>
[2] <Instruction 2>
[3] <Instruction 3>
[4] <Instruction 4>
[5] <Instruction 5>
"""
We also see that they even give the possibility to get rid of an instruction, if judged too complicated, with a score of 6. In the end, we have made our initial instruction evolve through diverse prompts, making it each time potentially slightly more complex and asking a model to rank all the evolved sequences together so we can have fine-grained scoring (C1, C2, C3, C4, C5 ) of instructions (I1, I2, I3, I4, I5 ).
Train an ad-hoc model to score all instructions
If we take a look back at our experimental set-up we want to score each of the instructions from our 300k instruction/response pairs. Nevertheless, we cannot apply the EVOL COMPLEXITY process to each of the 300k pairs. Otherwise, it’s most likely that all the original instructions will have a score of 1, and we will be at the starting point again, impossible to discriminate the complexity of any instructions. Therefore, the authors chose to use first a dataset of 2k observations as seeds to apply EVOL COMPLEXITY. They used the Alpaca dataset to randomly choose the instruction/response pairs. This means that they applied the EVOL COMPLEXITY process to automatically get from one instruction 5 evolved instructions and then rank them together.
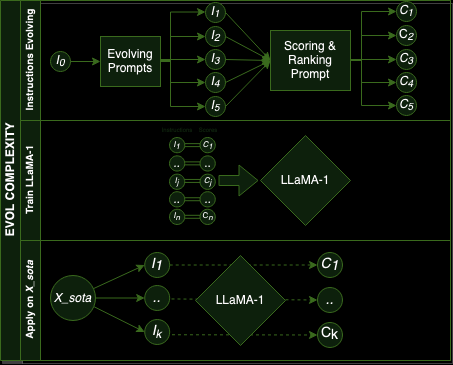
Steps for EVOL COMPLEXITY, from instruction evolving to scoring of each instruction in our data pool X_sota
Once they have those 12k instructions with different scores, they use the (instructions, scores) dataset to train a model, LLaMA-1 7B to learn how to score the complexity of any instruction/response pair. In a way, we can think about this training as the distillation of LLM knowledge: we have to learn what are the slight differences that make an instruction complex or not. The LLM scores from the first step are our teacher and the LLaMA-1 7B the student. We will come back on this point in our discussion afterwards about two different topics: the choice of LLaMA-1 7B and the knowledge it may have learnt from the scores.
After training this student model, we apply it to all instructions to score all our instruction-response pairs. And this is how we assess the complexity from a big stacked dataset we have collected at first!
Results when selecting the most complex instructions
To show the relevance of such an assessment method, the authors evaluated the MT-bench models fine-tuned with different data selections according to how we defined complex instructions. Each time they selected 6k data according to the complexity score:
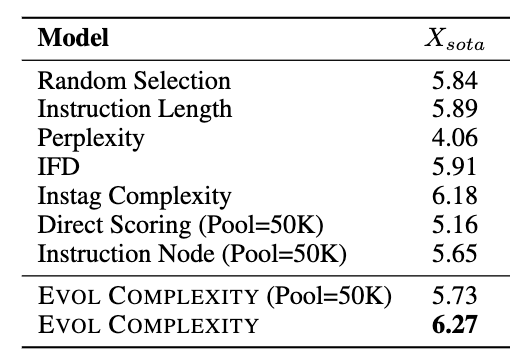
Credit: Lieu et al. (2023)
We see that the EVOL COMPLEXITY method performs the best, especially compared to random selection or instruction length, i.e. the longer the instruction the more complex it is. We see that the unique method quite equivalent is the Instag Complexity method. This method tags the instructions with different labels, and the higher the number of labels the more complex they consider the instructions. The process is relatively similar to the one used in EVOL COMPLEXITY as they train an algorithm to mimic LLM outputs, for tagging in this case.
Another interesting point is that the instruction length is quite better than some more complex methods, and we’ll get back to that later in our discussion.
But, finally, the results highlight the quality of such a way to evaluate the complexity of instruction and looks to be efficient when it comes to instruct-fine a LLM.
Quality Evaluation
Now that we have achieved scoring the complexity of the instructions, we will focus on the quality of the responses to assess good data. Similar to EVOL COMPLEXITY, the authors introduced EVOL QUALITY, a method based on LLMs, instead of humans, to automatically score the quality of the response. In the following steps, we will detail step by step how to use EVOL QUALITY:
Credit: Lieu et al. (2023)
As the steps are quite close tothe EVOL COMPLEXITY process, we will go a bit faster inthis step.
In-Depth Evolving Response
From any instruction-response pair, (I, R), the goal now is to make the response evolve into a more helpful, relevant or enriched response. The only difference is that we need to also provide the first instruction to guide evolution.
Let’s take back our example from GPT-4-LLM. Here we have the response response_0 and its initial instruction instruction_0:
instruction_0 = “Give three tips for staying healthy.”
reponse_0 = “1. Eat a balanced and nutritious diet: Make sure your meals
are inclusive of a variety of fruits and vegetables, lean protein, whole
grains, and healthy fats. This helps to provide your body with the essential
nutrients to function at its best and can help prevent chronic diseases.
2. Engage in regular physical activity: Exercise is crucial for maintaining
strong bones, muscles, and cardiovascular health. Aim for at least
150 minutes of moderate aerobic exercise or 75 minutes of vigorous exercise
each week. 3. Get enough sleep: Getting enough quality sleep is crucial for
physical and mental well-being. It helps to regulate mood, improve cognitive
function, and supports healthy growth and immune function. Aim for 7–9 hours
of sleep each night.”
Again the authors provided several prompts you could use to make your response evolve according to some guidelines. For example, this one was used to enrich the answer:
PROMPT = """
I want you to act as a Response Rewriter Your goal is to enhance the quality of the response given by an AI assistant to the #Given Prompt# through rewriting.
But the rewritten response must be reasonable and must be understood by
humans.
Your rewriting cannot omit the non-text parts such as the table and code in
#Given Prompt# and #Given Response#. Also, please do not omit the input
in #Given Prompt#.
You Should enhance the quality of the response using the following method:
Please make the Response more in-depth You should try your best not to make the #Rewritten Response# become verbose, #Rewritten Response# can only add 10 to 20 words into #Given Response#.
‘#Given Response#’, ‘#Rewritten Response#’, ‘given response’ and ‘rewritten response’ are not allowed to appear in #Rewritten Response#
#Given Prompt#:
<instruction_0>
#Given Response#:
<response_0>
#Rewritten Response#:
"""
Prompting this to an LLM, you will automatically get a more enriched response, called response_1, from an initial response response_0 and initial instruction instruction_0:
response_1 = “1. Consume a well-rounded diet: Incorporate a diverse array of
fruits, vegetables, lean proteins, whole grains, and beneficial fats into
your meals. This diversity ensures your body receives the vital nutrients
needed for optimal functionality and helps in warding off chronic health
conditions. 2. Commit to consistent physical activity: Regular exercise is
fundamental for sustaining robust skeletal and muscular health, as well as
cardiovascular vitality. Strive for a weekly total of 150 minutes of
moderate-intensity aerobic activity or 75 minutes of high-intensity
exercise. 3. Prioritize adequate sleep: Ensuring sufficient, quality sleep
is essential for both physical and mental health. It plays a key role in
mood regulation, cognitive performance, and supports the body’s growth
and immune responses. Target 7–9 hours of restful sleep per night.”
And now, as in EVOL COMPLEXITY you iterate through this path and use different prompts to make your responses more relevant, helpful or creative. In the paper, they make 4 more iterations to get 5 evolved responses (R0,R1, R2, R3, R4 ) which makes 5 different responses for one initial instruction at the end of this step!
Rank and Score quality
We process the responses with instructions the same way: we ask an ad-hoc LLM to score the 6 responses and we provide the 5 responses at the same time to enable the LLM to discriminate between response quality. The reasoning we had for instructions remains: if scoring independently all responses it is most likely that the LLM will provide a similar score in the end making our process obsolete.
instruction_0 = “Give three tips for staying healthy.”
response_0 = “1. Eat a balanced and nutritious diet: Make sure your meals are
inclusive of a variety of fruits and vegetables, lean protein, whole grains,
and healthy fats. This helps to provide your body with the essential
nutrients to function at its best and can help prevent chronic diseases.
2. Engage in regular physical activity: Exercise is crucial for maintaining
strong bones, muscles, and cardiovascular health. Aim for at least 150
minutes of moderate aerobic exercise or 75 minutes of vigorous exercise
each week. 3. Get enough sleep: Getting enough quality sleep is crucial for
physical and mental well-being. It helps to regulate mood, improve cognitive
function, and supports healthy growth and immune function. Aim for 7–9 hours
of sleep each night.”
response_1 = “1. Consume a well-rounded diet: Incorporate a diverse array of
fruits, vegetables, lean proteins, whole grains, and beneficial fats into
your meals. This diversity ensures your body receives the vital nutrients
needed for optimal functionality and helps in warding off chronic health
conditions. 2. Commit to consistent physical activity: Regular exercise is
fundamental for sustaining robust skeletal and muscular health, as well as
cardiovascular vitality. Strive for a weekly total of 150 minutes of
moderate-intensity aerobic activity or 75 minutes of high-intensity exercise.
3. Prioritize adequate sleep: Ensuring sufficient, quality sleep is essential
for both physical and mental health. It plays a key role in mood regulation,
cognitive performance, and supports the body’s growth and immune responses.
Target 7–9 hours of restful sleep per night.”
To score together the responses you can prompt the LLM with this kind of guidelines, presented at the end of the paper:
PROMPT = """
Rank the following responses provided by different AI assistants to
the user’s question according to the quality of their response.
Score each response from 1 to 5, with 6 reserved for responses that
are already very well written and cannot be improved further.
Your evaluation should consider factors such as helpfulness,
relevance, accuracy, depth, creativity, and level of detail of the response.
Use the following format:
[Response 1] Score:
[Response 2] Score:
#Question#:
#Response List#:
[Response 1] <Response 1>
[Response 2] <Response 2>
[Response 3] <Response 3>
[Response 4] <Response 4>
[Response 5] <Response 5>
"""
Again the authors give the possibility to get rid of a response, as they did for an instruction, if judged too good, with a score of 6. Thus in the end, we have automatically created sequences of evolved responses with slight differences and the LLM has assigned fine-grained quality scores by considering all potential responses at the same time.
Train an ad-hoc model to score all responses
As the authors did with complexity evaluation, before assessing the quality of each response regarding its instruction in the 300k observations, we need first to use a seed dataset to compute the EVOL QUALITY process to rank and score responses. Next, we will use the same distillation process to make a LLaMA-1 7B model to learn how to score the quality of any instruction-response pair. The only difference with the previous process is that we have a dataset of (instruction-response, score) to learn how to score instead of the (instruction, score) only to score complexity.
Once trained, we apply the model on all the instruction-response pairs and we have a score to rank all our dataset.
Results when selecting most qualitative responses
Again, to show the relevance of EVOL QUALITY method, the authors evaluated on the MT-bench models fine-tuned with different data selections according to how we defined quality responses according to an instruction. Each time they selected 6k data according to the quality score:
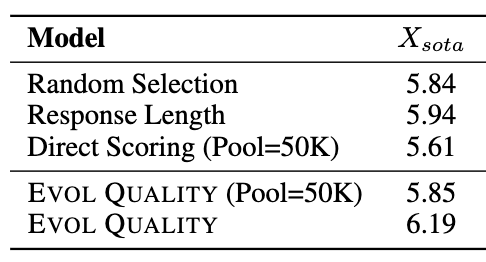
Credit: Lieu et al. (2023)
The score is much better when selecting data with the EVOL QUALITY method than when we select randomly or according to the length, making a more qualitative response if longer. Nevertheless, we see that the margin we may have seen in the complexity score is thinner. And we’ll discuss the strategy in a later part.
Nevertheless, this strategy looks to improve the fine-tuning compared to the baselines and now we’re interested in mixing quality and complexity assessment with a diversity evaluation to find the right trade-off in our selection process.
Diversity factor
One main component of good data to instruct-tune the LLM lies in the diversity of the data. The authors mentioned a study which real-world data often has redundancy. And generally, redundancy may guide your model to overfitting or bad generalization. Therefore they proposed a way to ensure diversity across the selected observations.
An iterative process
The method to ensure diversity in your final 6k observations relies on an iterative procedure. The main idea is to begin with an empty set of observations S = {}, and select (randomly) one observation (instructioni, responsei) among your pool of data and assess whether this observation contributes to diversity or not. At first, as the set is empty you will add the first observation. Thus we have S = {(instructioni, responsei)} and we will select another observation (instructionj, responsej), and make it pass a filter Ƒ called Repr Filter. This filter outputs whether the new observation contributes to the diversity of the final set S. More formally, we have:
Ƒ(instruction_k-response_k, S) = 1 then we add instruction_k-response_k in S, otherwise we don’t.
And we repeat this procedure till we reach our final budget, i.e., the maximum number of instruction-response pairs to instruct-tune our LLM.
An embedding approach
The authors considered an embedding approach to build the filter Ƒ. Word embedding, the representation of words into a vector/numerical space, should represent words according to their semantic properties and their context. If you’d like to dive into embedding understanding, we encourage you to go for Alammar blog posts on Word2Vec or on BERT. The embedding space, a vector space, will help in considering distances between different sentences or words.
In this case, the LLaMA-1 13B was used to encode all instruction-response pairs into an embedding space. Once you’ve computed the embedding of each instruction-pair, you will be able to calculate the distances between one random point in your data pool X_sota and its nearest neighbor in the final set S. In other words, the filter used to assess if an observation contributes to the diversity of the final set S depends on the cosine distance between this point and the set S. Formally speaking, here is what it looks like:
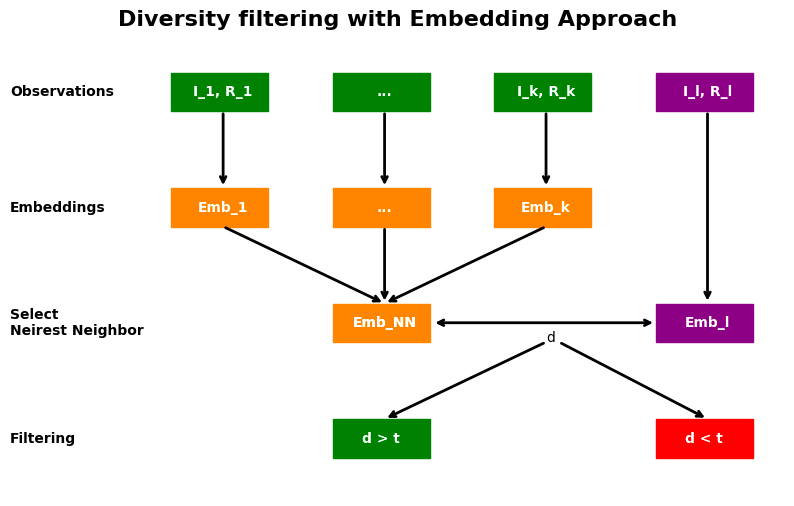
Representation of the embedding approach
Our set of instruction-response pairs already have some observation S = {(instruction_1, response_1), …, (instruction_k, response_k)} with k < m our final budget (in green in the picture). We already have all the embeddings according to those pairs. When we select a new observation (instruction_l, response_l), in purple, we compute the embedding of this pair. Then we select the closest point within the set S and finally, we compare the cosine similarity between the Emb_NN the embedding of the nearest neighbor of observation l and the embedding of the observation l. Depending on the cosine distance, you add this observation into the final set S.
Results regarding the diversity perspective
To compare the efficiency of this method, the proposed baseline is the random selection and also the Instag diversity, again the same paper we talked about earlier. Here the diversity of a new observation is considered if an observation adds a new tags in all tags present in the final set S. Here is a table of the results:

Credit: Lieu et al. (2023)
Again the diversity strategy looks to be quite better than random selection and even the Instag Diversity strategy.
Combining everything
In a nutshell, we saw that the authors introduced: EVOL COMPLEXITY and EVOL QUALITY ways to automatically score the data according to quality and complexity. Besides, they presented a methodology to select diverse data with an embedding approach. So now, the main objective is to combine the three dimensions together to have the best results.

Credit: Lieu et al. (2023)
We can go for the easiest path, as in the article. In the previous part, we randomly chose the observations to assess their diversity contribution to the final set. Now we will rank our pull of data X_sota according to a final scores which represents at the same time the quality and the complexity scores. To compute this final score s we will simply multiply the quality score q with the complexity score c for each instruction-response pair. Then we can order the dataset according to the final scores and go through each observation in descending order to look for observations that will contribute to the diversity of our dataset.
We have gone through all the steps to compute the final dataset we will use to instruct-tune our LLM with a budget constraint. And as mentioned above, with only 6k observations selected according to the dimensions of diversity, quality and complexity, we reached really competitive results!
Main questions related to the paper
In this step we consider some questions related to the methodology and try to give some path of investigation to adapt to your own use case.
Correlations between complexity and quality
First, we’d like to dive into how the paper defines complexity and quality dimensions. We can’t help but notice that the instructions and responses evolution often goes along with increasing the size of the instruction or the response. For instance, when it comes to instructions, two prompts to increase instructions’ complexity clearly state to add reasoning steps or constraints. And even if the other prompts mention not to “add more than 10 or 20 words”, it looks like the trend to increase prompt length through the process. We present here an example using openAI gpt-4 from an original instruction and evolving through the DEITA prompts to make instruction more complex:
instruction_0 = “Give three tips for staying healthy.”
adding constraint
instruction_1 = “Provide three recommendations for maintaining well-being,
ensuring one focuses on mental health.”
deepening
instruction_2 = “Offer three nuanced strategies for sustaining overall health,
with an emphasis on enhancing psychological wellness, incorporating at
least one method that specifically targets stress reduction.”
concretizing
instruction_3 = “Propose three detailed approaches for optimizing
holistic health, prioritizing the improvement of mental well-being, and
include a specific technique aimed at mitigating stress through mindfulness
or cognitive-behavioral practices.”
increasing reasoning steps
instruction_4 = “Suggest three comprehensive strategies for enhancing overall
wellness, with a focus on mental health enhancement, and detail a multi-step
method that employs mindfulness or cognitive-behavioral techniques for
feffectively reducing stress levels.”
Even if the LLM scorer is not necessarily going to give the highest score for the longer instruction, we can think that the more it goes through the transformation, the more complex the instruction becomes and this trend may be reflected into the final complexity score.
Another point we noticed is how authors compute the score for dialogues:
In the case of multi-turn dialogues, we score each turn separately and use the sum of them as the final score.
Again, it looks like the length may be an important factor as adding scores with the number of turns would mean the higher the number of turns, the higher the score. Thus it’s possible to have non-informative dialogue turns with high complexity or quality scores because of the number of turns and not so much because of the contents. Besides, we also see that the length baselines, i.e. scoring complexity or quality according to instruction-response length, to select data were not so bad compared to the final strategy.
In other words, we think that both quality and complexity calculation may be influenced too much by their length. We might recommend controlling this variable to reduce its importance in the final selection to be sure to have high qualitative content, which is more complex because of its way of reasoning than because of its length. There is some work on how to deal with length in statistics literature we could draw inspiration from. For instance, the adjusted R2 for linear regression, to avoid looking at a metric, R2, that is driven by the number of explanatory variables in the model. Another example is the BM25, an extension of TF-IDF, that takes into account the length of a sentence to control the length bias when computing final weights.
Distance in high dimensions
To filter the diversity, the authors chose to go for an embedding approach with the LLaMA-1 13B model to encode the instruction-response pairs. This approach makes sense, considering distances in Euclidean spaces is intuitively a good approach. Nevertheless, there is a limitation here is the dimensionality of the embedding space.
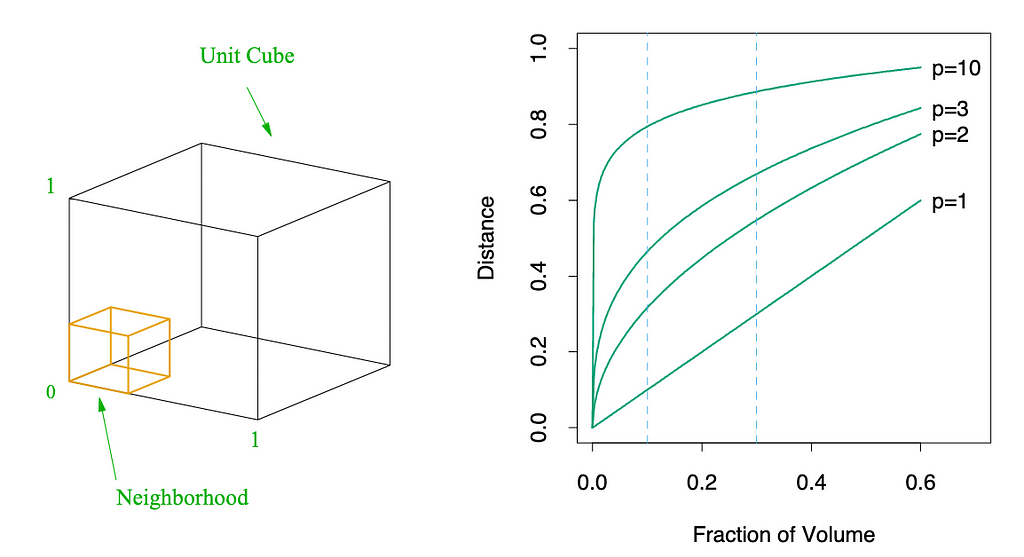
Credit: Hastie et al. (2009)
Indeed, the embedding space of models such as LLaMA or BERT is generally higher than 500. But generally, in such high dimensional space, the space is essentially empty. Let’s take the example from The elements of Statistical Learning about the curse of dimensionality: in high-dimensional spaces, like a 10-dimensional unit hypercube, finding the nearest neighbours to a point for local averaging requires covering a large portion of the entire space, making the neighbourhood not truly “local.” For example, to capture just 1% or 10% of data points, one must span 63% or 80% of the input variable range, respectively. The median distance to the nearest data point in a high-dimensional space (e.g., 10 dimensions with 500 data points) can be over halfway to the boundary, indicating that data points are more isolated. Furthermore, maintaining the same sampling density in higher dimensions exponentially increases the required sample size, illustrating the “curse of dimensionality” where high-dimensional spaces are inherently sparse. Therefore with this number of samples, maybe the idea of cosine distance is not the best. Some analysis on this dimension may be quite interesting to challenge this approach. Maybe some dimension reduction techniques such as UMAP could have been performed before going into the distance analysis.
Use as LlaMA-1 7B to distill the scoring distribution
One other point we may want to investigate more is the choice of the LLaMA-1 7B to score each instruction of the data pool for EVOL COMPLEXITY and each (instruction, response) for EVOL QUALITY. Indeed, it would have been interesting to motivate this choice regarding the main constraint: your budget. Following the same idea of limiting the budget to allocate, one may try to fine-tune a smaller model to save development costs. For instance, a BERT-like model may have been suited for these kind of tasks. Additionally, the BERT model would have gone faster and cost much less when scoring 300k pairs of instruction-response. It might also be possible that BERT-like models can’t really get the nuances that have been generated by the evolved instructions and responses. Anyway, a study on this point, looking into performance, speed, computations and model size would have been interesting to extend the work regarding the budget constraint and also provide some insights on the capacity of such models to generalize such complex tasks.
Sustainability considerations
One personal regret regarding the paper is around sustainability considerations. There is not. The authors really take into account the budget for training an LLM, which may be correlated, but as mentioned in several papers, Strubell, Stochastic Parrot or more recently in BLOOM, this kind of consideration is key for AI sustainability in the long term. And the regret is that the data-centric strategy, which tries to use as few resources as possible, could have gotten more perspective on the climate crisis we live in everyday. And papers which focus on such techniques should highlight the sustainability problem at some points to show new ways of innovating.
Conclusion
In conclusion, if you are looking for some efficient method to align an open-source LLM to your business case with a constrained budget, the solutions provided by DEITA are really worth the shot. This data-centric approach enables one to focus on the content of the dataset to have the best results instead of “just” scaling the instruction-tuning with more, and surely less qualitative, data. In a nutshell, the strategy developed, through automatically scoring instructions-responses, aims to substitute the human preference step proprietary models such as GPT-4 have been trained with. There are a few improvements we could think about when it comes to how to select the good data, but it opens a really great way in instruct-tuning LLM with lower computational needs making the whole process intellectually relevant and more sustainable than most of the other methods. We’d be happy to help you out with aligning an LLM with your business case drawing inspiration from such a methodology.
Fine-tuning Large Language Models on a budget with DEITA was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.
