Organizations with a large collection (corpus) of documents often need to find similar documents. For a grant-giving organization (for example a charitable foundation like the Wellcome Trust), the use case could be finding experts to review grant applications by matching the expert’s publication history to the grant application. For a law firm, the use case could be finding the closest legal precedent to a given court case. Fortunately, retrieving similar documents is a well studied natural language (NLP) problem; Google, for example, has to solve that problem for the entire web.
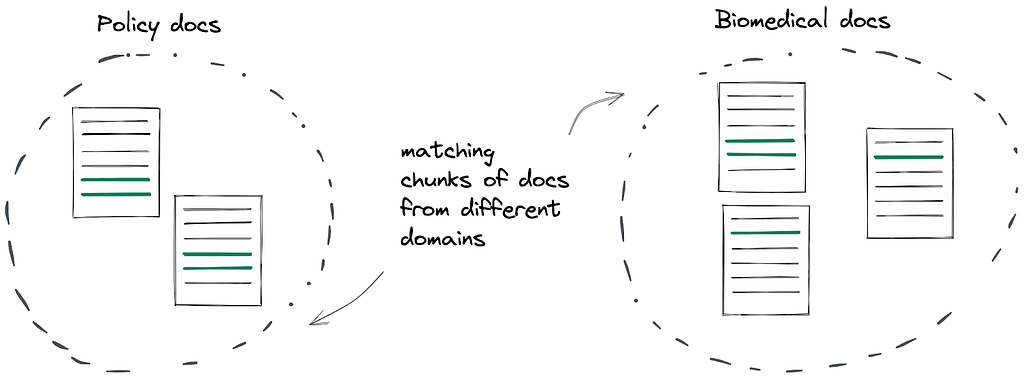
The challenge: matching document chunks from different domains
An interesting subproblem of document similarity is matching a document chunk, for example a sentence or paragraph, with another document chunk that refers to something similar. This is relatively trivial when the chunks come from documents with very similar context but is much harder if the documents come from different fields, and use a different vocabulary and syntax. Let’s take a look at an example from the policy domain that contains a reference to a biomedical publication to visualize the problem
The following sentence appears in the WHO Guidelines for Malaria. This document comes from the policy domain, i.e. it is published by an organization that sets policy that is adopted by other organizations across the globe.
The systematic review [54] reported high-certainty evidence that, compared to no nets, ITNs are effective at reducing the rate of all-cause child mortality.
The sentence from the document above refers to a sentence in an scientific journal article in the biomedical domain:
Possible benefits: using insecticide-treated nets was found to possibly reduce the risk of fetal loss (RR 0.68, 95% CI 0.48 to 0.98; 5 RCTs; high-certainty evidence)
As we can see the language used is very different. ITNs are spelled out as insecticide-treated nets; child mortality has become fetal loss; rate is referred to as risk and there is no mention of a control group (no nets). For traditional information retrieval systems, which rely on keywords, finding a link between these two sentences would be challenging. Making these connections requires a new approach that is able to understand that the semantics of the texts are similar, even if the words used are quite different.
This is not an uncommon case, linking texts from different domains is a common problem. For example, we also come across this problem when relating patents to legal cases, grant application synopses to research publications, and policy documents with the documents they reference.
So how can we use a model to make those connections? This is where language models come in.
What are language models?
Language models are machine learning models that capture information about the patterns that occur in language, usually by training them to predict the next word in a sequence, or randomly removed (masked) words within a document. Language models are typically trained in a specific domain, and they are quite good at modeling the language of that domain.
For example, there is a language model trained using biomedical publications from PubMed called PubMedBert, and another trained using contracts and European law documents from EurLex called LegalBert. These models have the ability to create a semantic representation of a text: a representation based on the meaning, not just the words used (syntax). This makes it possible to retrieve the closest text chunks in terms of meaning, which is exactly what we want.
Typically these models do not work well outside their specific domain, so in the example we gave earlier of matching chunks from policy documents to scientific publications in the biomedical domain, we need both a model trained on policy documents, and a model trained on biomedical publications. We could use PubMedBert for the biomedical publications, but there is not currently a language model trained on policy documents that is openly available, so we would need to train our own model.
Linking text chunks from different domains using language models
Once we have a language model for both domains, we can proceed to calculate similarities between document chunks. In order to do that, we need to ensure that the representations produced from those documents are in the same “space”. Since those models have only seen data from their respective domain, they have no way to know when the meaning of a chunk aligns with the meaning of a chunk from another domain. We need some examples to do this linking. You can think about it as if our two models are speaking different languages, like English and Spanish. To train a translation model, we would need pairs of English and Spanish sentences matched by meaning. Equally to ‘align’ the representations from our two document domains, we need pairs of chunks that have been matched by their meaning (usually by a person). Finding or creating that dataset is usually the hardest part of such a project.
Once we have aligned our two domain specific language models, we are ready to use them for matching chunks from our documents by finding the most similar chunks using the aligned representations and a similarity metric. Alternatively, we can also train a model to predict whether two chunks match using the same representations as inputs and the same dataset used to align them.
I hope you enjoyed this post and it is now clearer how language models can help you in seemingly difficult cases of document matching where the semantics play an important role. If you need help with such a problem or you want to talk to us more about this, feel free to reach out at hi@mantisnlp.com.
P.S. Another important aspect here, which we have glossed over in this blog post is how to break an entire document into chunks — for example sections or sentences. This can be a difficult problem, and may end up being a project in its own right.