Speed up ️ data annotation with active learning ✨
Categories:
Access to high quality annotated data remains one of the biggest limiting factors preventing companies from progressing an AI use case into a working implementation. This is despite great advances in few shot learning and pre-trained models which lower the barrier to entry and reduce the amount of annotated data required to reach an acceptable performance. It is still the case that for most AI tasks in industry, you need a good amount of annotated data to reach close to state-of-the-art performance.
Annotating data is time consuming and laborious. This increases the time needed to deliver a working solution and can add a significant cost to the project. One popular but often overlooked way to speed up your data annotation is through active learning.
What is active learning? ✨
Active learning is one of those techniques that everyone talks about in AI circles but few use in practice. This is unfortunate because it has the potential to dramatically speed up your data annotation process and thus reduce the time taken to reach a performant solution. So how does active learning do that?
The standard approach to data annotation is to annotate a randomly selected sample of your data and then to train and evaluate your model; this is repeated until the model has the performance you want. Annotating a random sample is a good idea because it ensures that the annotated data follows the same distribution as the data you did not annotate, so it’s more likely that the model will generalize to those examples and perform as well as expected.
With active learning on the other hand, instead of annotating a random sample, you annotate a portion of the examples that are most useful to improving the model. This should enable your model to reach a certain level of performance with less data.
Deciding on the examples are useful for active learning
There are a couple of ways to decide which examples are the most useful, but one popular way to choose is to select the ones that a model is more uncertain about i.e. its probability estimates are close to 0.5. As you continue to annotate, your annotations are used to update the underlying model. This in turn changes which examples the model finds the most uncertain, making sure that you keep annotating only those examples that can benefit the model the most.
Be cautious of biasing your model
Active learning’s main advantage is also its limitation. Annotating the most uncertain examples can break the assumption that the dataset is representative of real world data. In fact our annotated dataset is a “biased” sample of the original data. At the very least, this means that the annotated dataset is better suited for the underlying model but can also have a negative impact on performance more generally, so active learning should be used with caution.
How to use active learning? 🪄
Other than the fact that active learning is not a silver bullet, another reason it might not be so prevalent in practice is that few annotation tools support it out of the box. Prodigy, which is made by the same people behind SpaCy (a very popular open source NLP library) comes with active learning baked in. Prodigy has gone a step further and implemented a binary active learning annotation scheme which makes data annotation even more efficient. How does binary annotation differ from standard active learning? Let’s see a Named Entity Recognition example from the demo page.
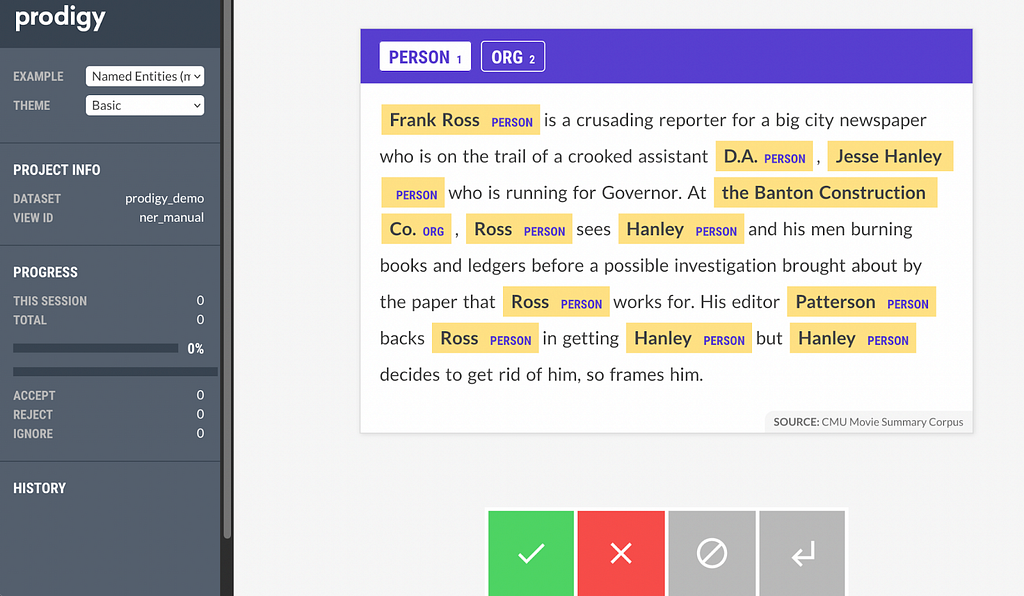
Typically active learning’s job would be to reorder the examples for you, so that you spend more time annotating the most impactful ones. But annotating, or correcting the model annotations, still takes up a lot of mental time as you can see from the examples above. This is because you need to carefully scan the example and make sure you have not missed a correction, which can take up to minutes per example.
Binary annotation instead only asks you about one entity at a time, for example ORDINAL in the example below.
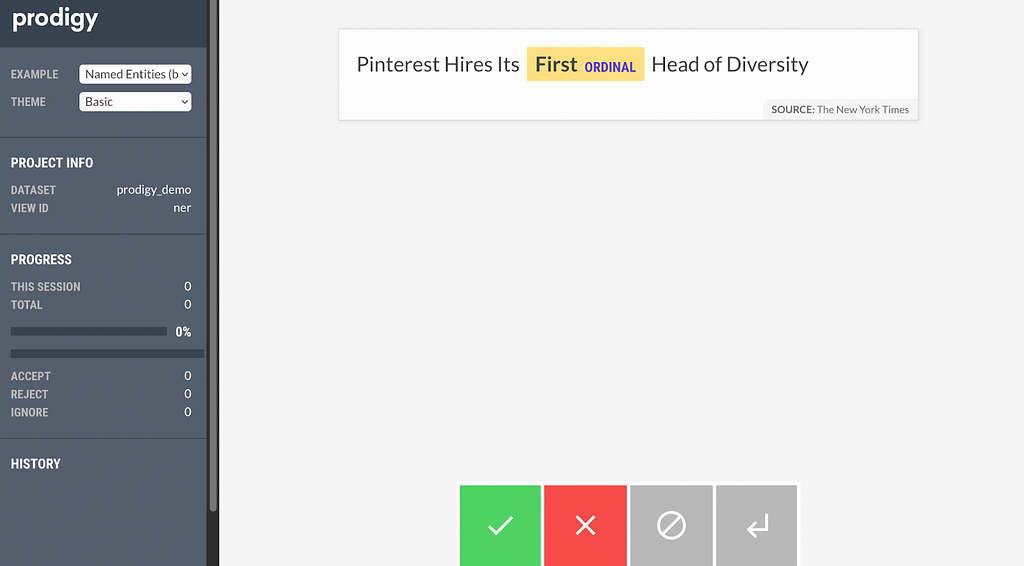
This makes it really fast to annotate as you only need to make one decision at the time. Even though you might need to revisit the same example multiple times, one per entity that the model is uncertain about, it still makes moving through examples much quicker, often in just a few seconds.
How do I start? 🤔
Active learning suffers from a cold start problem. If there is no model for your entity or class, then you cannot use it to find the most informative examples to annotate. More often than not though this is not the case since nowadays there are numerous of pre trained models for pretty much anything. Prodigy in particular integrates well with both spaCy and huggingface so it’s easy to use models from their respective hubs out of the box. Prodigy is also easily hackable so you can extend it to use any model by writing a custom recipe (see here if you want to know how).
Your best bet
When there are no pre-trained models to choose from, your best bet is to annotate a few examples and train a base model before you kick off the active learning process. Alternatively you can also use patterns or a rule based system as your model in the loop before training your first statistical model (you can read more about this here).
Wrap up 🏎️
In this post, we talked about active learning and how it has the potential to speed up your data annotation effort. We dived a bit deeper into Prodigy and how binary active learning is an even more efficient way to do active learning. We also briefly touched on how you can start the active learning process with or without a pre-trained model. Hope you enjoyed the post. If you have any questions or have interest in using active learning in your projects, do not hesitate to contact me at hi@mantisnlp.com.
Speed up 🏎️ data annotation with active learning ✨ was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.