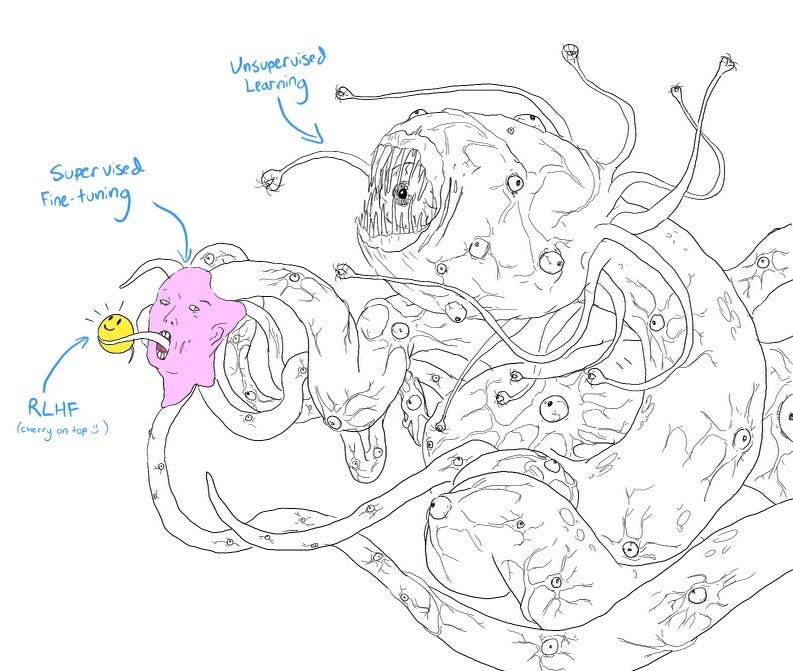
Supervised Fine-tuning: customizing LLMs
Categories:
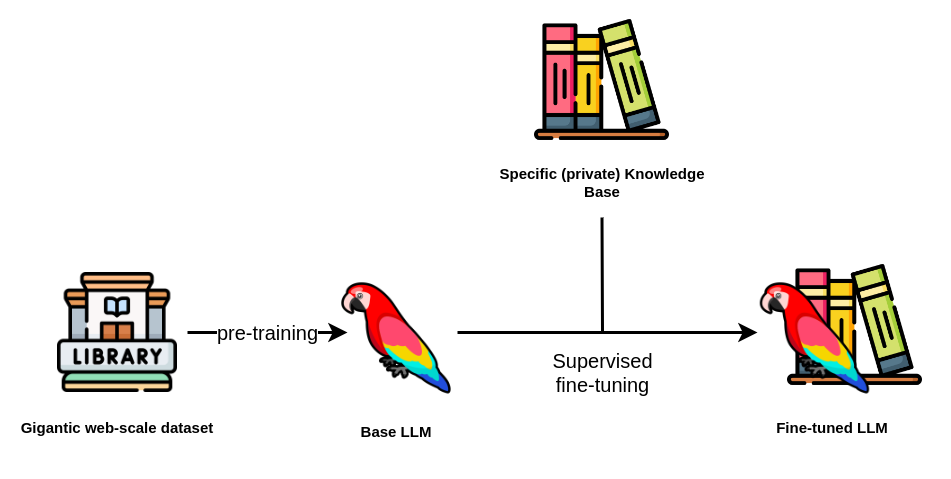
Supervised Finetuning on LLMs. Source: Neo4j
In the rapidly evolving field of Natural Language Processing (NLP), fine-tuning has emerged as a powerful and effective technique to adapt pre-trained Large Language Models (LLMs) to specific downstream tasks. Pre-trained large-scale language models (as GPT family) have shown significant advancements in language understanding and generation. However, these pre-trained models are typically trained on vast amounts of text data with unsupervised learning and may not be optimized for a specific task.
Fine-tuning bridges this gap by taking advantage of the general language understanding captured during pre-training and adapting it to a target task through supervised learning. By fine-tuning a pre-trained model on a task-specific dataset, NLP practitioners can achieve impressive results with significantly less training data and computational resources than training a model from scratch. Specifically, for Large Language Models, finetuning is crucial, as a retraining step with the whole data is computationally prohibitive.
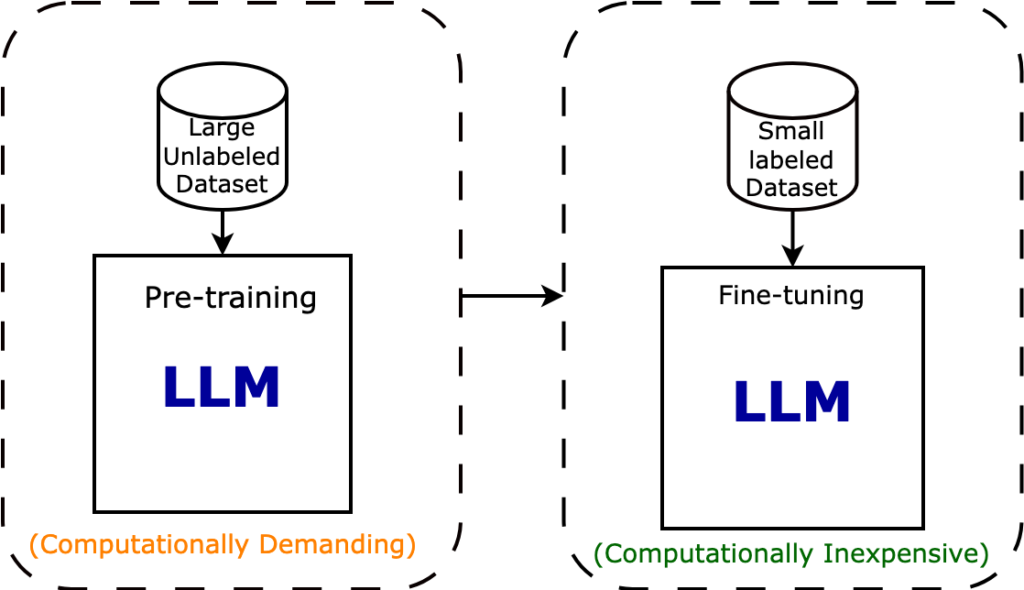
(Pre)training an LLM vs Fine-tuning. Source: Intuitive Tutorials
The success of fine-tuning has led to numerous state-of-the-art results across a wide range of NLP tasks and has become a standard practice in the development of high-performing language models. Researchers and practitioners alike continue to explore variations and optimizations of fine-tuning techniques to push the boundaries of NLP capabilities further.
In this article, we will delve deeper into the process of fine-tuning an Instruction-based Large Language Model using transformers library in two different ways: with just the basic transformers library and with the trl module.
Supervised fine-tuning (SFT)
Supervised fine-tuning, involves adapting a pre-trained Language Model (LLM) to a specific downstream task using labeled data. In supervised fine-tuning, the finetuning data is collected from a set of responses validated before hand. That’s the main difference to the unsupervised techniques, where data is not validated before hand. While LLM training is (usually) unsupervised, Finetuning is (usually) supervised.
During supervised fine-tuning, the pre-trained LLM is fine-tuned on this labeled dataset using supervised learning techniques. The model’s weights are adjusted based on the gradients derived from the task-specific loss, which measures the difference between the LLM’s predictions and the ground truth labels.
The supervised fine-tuning process allows the model to learn task-specific patterns and nuances present in the labeled data. By adapting its parameters according to the specific data distribution and task requirements, the model becomes specialized in performing well on the target task.
For example, let’s suppose you have a pretrained LLM. To the input I can’t log into my account. What should I do? it answers with a simple Try to reser your password using the “Forgot Password” option.
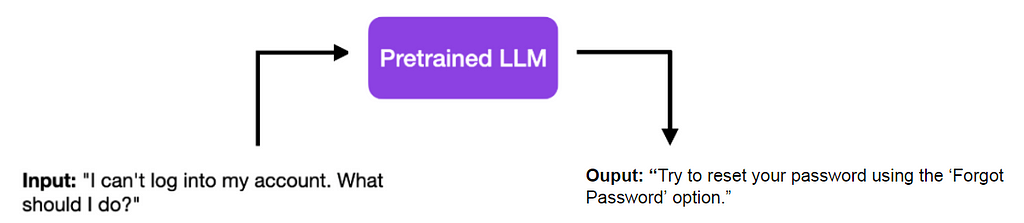
A dry and concise answer to a Customer Support question, using Pretrained LLMs.
And now imagine you want to build a chatbot for a Customer Support service. Although the answer below may be correct, it is not adequate as it is as a Customer Support answer, which would require more empathy, a different format, additional contact details, or whatever your guidelines are. This is when Supervised Finetuning comes into play.
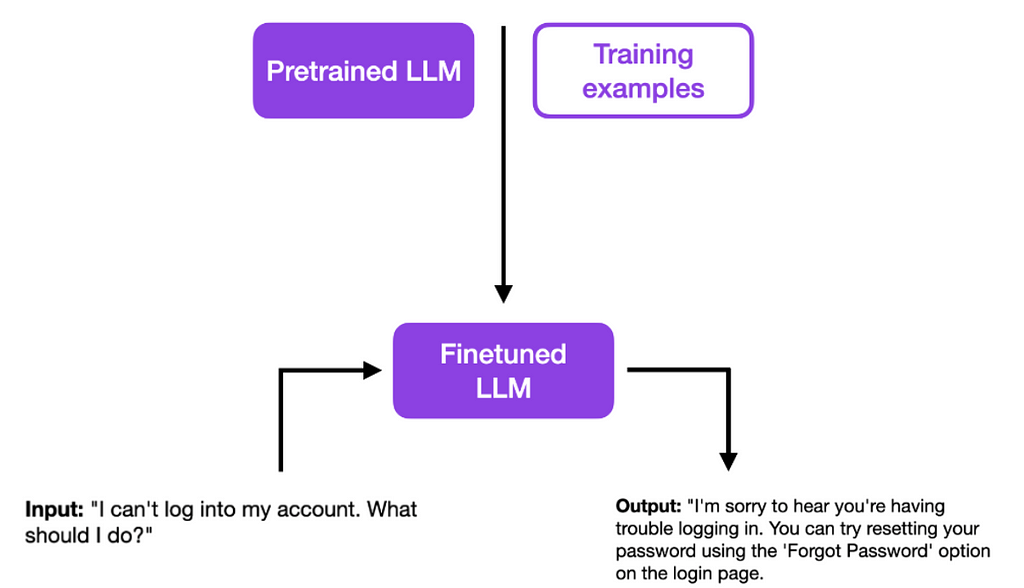
A better answer to a Customer Support question matching some guidelines, after Finetuning.
By providing a series of validated Training Examples, your model can learn to answer better to prompts are questions. In the example of the illustration below, we taught the model some Customer Support empathystatements**.**
Some of the reasons you may want to use finetuning of LLMs are:
- Achieve better answers, matching your business guidelines, as explained above.
- Provide new specific / private data, which were not available publicly during the training step, so that the LLM model is adapted to your specific knowledge base.
- Teach the LLM to answer new (unseen) prompts;
Supervised fine-tuning (SFT) using Transformers Library
Hugging Face’s transformers library has become by far the most used library to train and finetune models, including LLMs. Finetuning models has always been one of its core capabilities, and is almost transparently included in the Trainer facilitator class.
However, recently, with the creation of the trl module for Reinforcement Learning, a new class called SFTTrainer was released, which is more specific for Supervised Fine-tuning on LLMs. Let’s see the difference between both.
Finetuning using Trainer class
The Trainer class facilitates the pretraining and finetuning of models, including LLMs. It requires the following arguments:
- a model, loaded with AutoModelWithLMHead.from_pretrained;
- TrainingArgs;
- a train dataset and an evaluation dataset;
- a Data collator, which applies different transformations to the datasets. _Padding (_to create batches of the same length) is one of them, but this can also be performed by the tokenizer. In case of LLMsthere is another usage though, which makes it mandatory in this type of training — the masking of random tokens for next-token prediction.
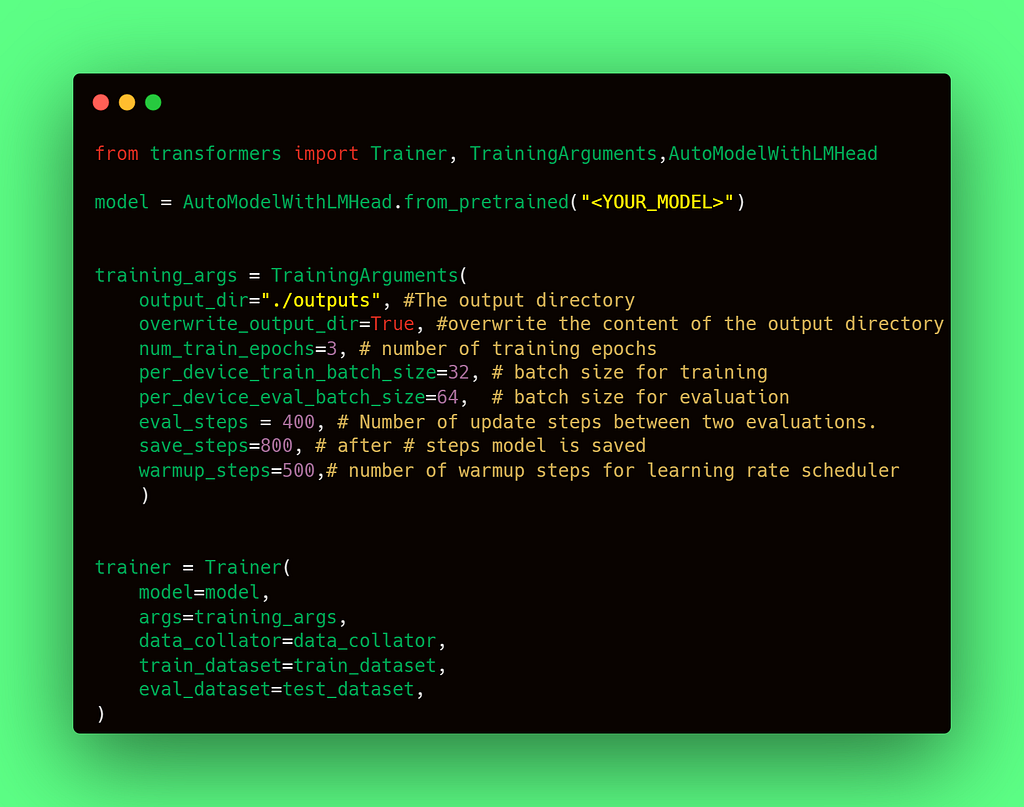
Finetuning a pretrained LLM with Trainer class
eval_dataset and train_dataset are objects of Dataset class. You can create Datasets from many different formats. In this case, let’s suppose I have the datasets in two txt files at <TRAINING_DATASET_PATH> and <TEST_DATASET_PATH> . Then to get the Datasets for both splits and also the Collator, just do:
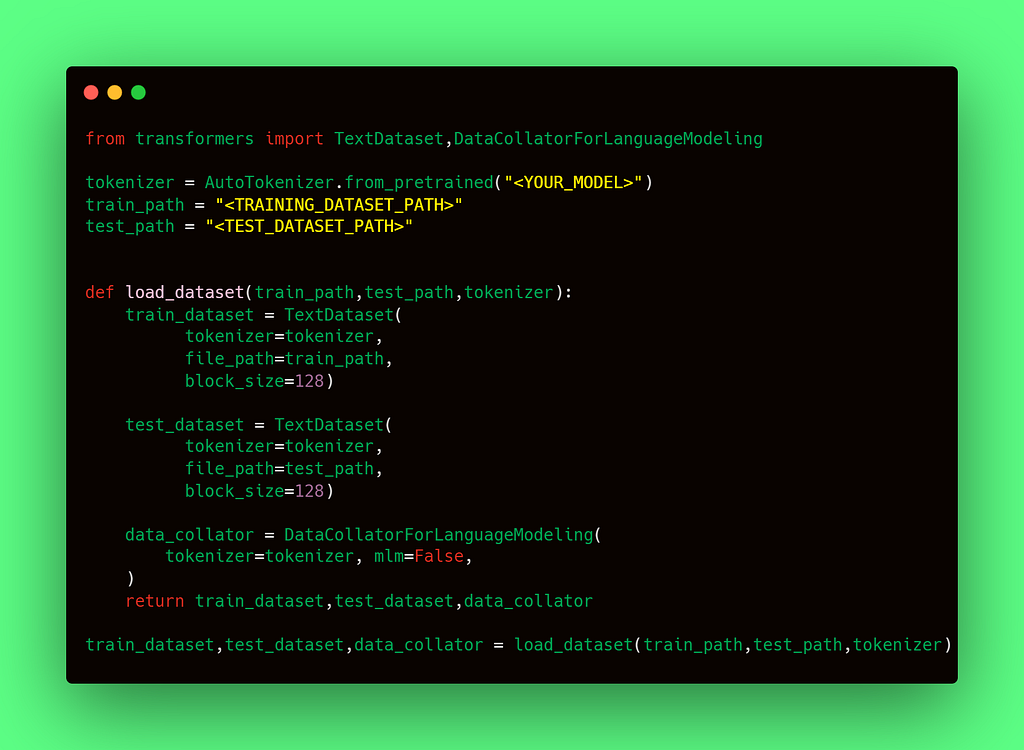
Preprocessing the data is a required step before training
If you want to train a Instruction-based LLM, here are some datasets you might find useful:
- GPT-4all Dataset: GPT-4all (Pairs, English, 400k entries) — A combination of some subsets of OIG, P3, and Stackoverflow, covering general QA and customized creative questions.
- RedPajama-Data-1T: RedPajama (PT, Primarily English, 1.2T tokens, 5TB) — A fully open pretraining dataset following LLaMA’s method.
- OASST1: OpenAssistant (Pairs, Dialog, Multilingual, 66,497 conversation trees) — A large, human-written, human-annotated high-quality conversation dataset aiming to improve LLM responses.
- databricks-dolly-15k: Dolly2.0 (Pairs, English, 15K+ entries) — A dataset of human-written prompts and responses, featuring tasks like question-answering and summarization.
- AlpacaDataCleaned: Some Alpaca/ LLaMA-like models (Pairs, English) — Cleaned version of Alpaca, GPT_LLM, and GPTeacher.
- GPT-4-LLM Dataset: Some Alpaca-like models (Pairs, RLHF, English, Chinese, 52K entries for English and Chinese, 9K entries unnatural-instruction) — Dataset generated by GPT-4 and other LLM for improved Pairs and RLHF, including instruction and comparison data.
- GPTeacher: (Pairs, English, 20k entries) — A dataset containing targets generated by GPT-4, including seed tasks from Alpaca and new tasks like roleplay.
- Alpaca data: Alpaca, ChatGLM-fine-tune-LoRA, Koala (Dialog, Pairs, English, 52K entries, 21.4MB) — A dataset generated by text-davinci-003 to enhance language models’ ability to follow human instruction.
Finetuning using `trl` SFTTrainer class
As mantioned above, there is another class, called SFTTrainer , which was later on included in Hugging Face’s trl library dedicated to Reinforcement Learning. As Supervised finetuning is the first step in Reinforcement Learning by Human Feedback (RLHF), the developers found a motivation for it to be isolated in its own class, adding at the same time some facilitating functions you needed to do manually if just using the Trainer library. Let’s see how it looks like.
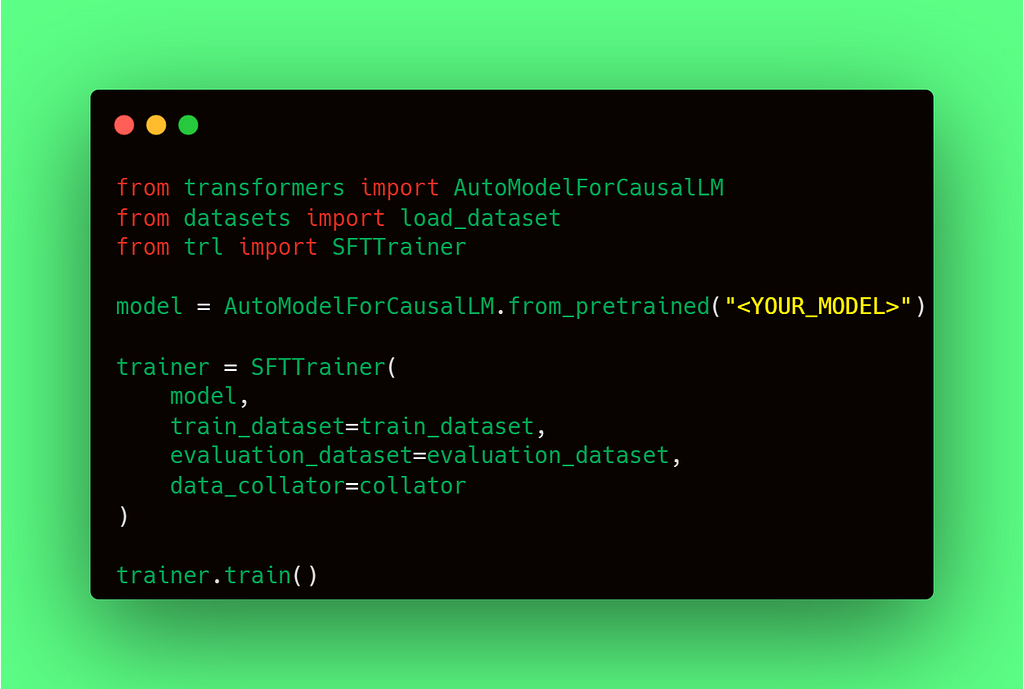
Finetuning a pretrained LLM with trl.SFTTrainer class
You may have not noticed anything new in the above example. Inded, you are right, since the SFTTrainer class inherits from the Trainer function, if you check the source code. Basically, same model, train_dataset, evaluation dataset and collator are required.
However, there are some capabilities added to the SFTTrainer class which facilities the training when working with LLM. Let’s enumerate them:
- Support of peft : In SFTTrainer there is support of the Parameter Efficient Finetuning library, which includes Lora, QLora, etc. Lora allows you to add Adapters with weights, which are the only parameters being fine-tuned, while freezing the rest. QLora is the quantized version. Both approaches improve a lot the finetuning time, which is specially relevant when finetuning LLMs because of the big computational cost.
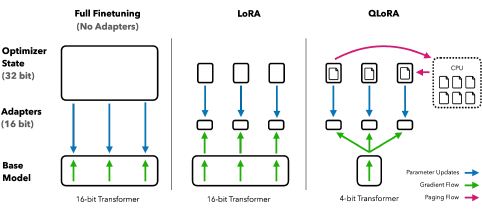
Finetuning vs Lora vs QLora
- Batch packing: Instead of using the Tokenizer to pad your sentences to the max length supported by your model, packing allows you to combine inputs one after another which increases batch capabilities.
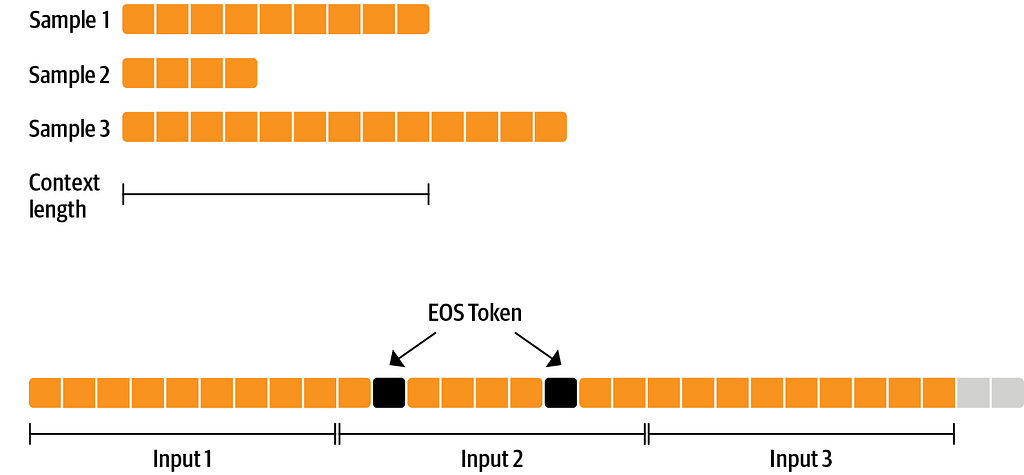
Samples 1,2,3 packed
Conclusions
Fine-tuning has historically been a mechanism to get the best of Transformers architectures. Either if you need to train a Language Model for the next token prediction and/or masking, or if you want to train a sequence, token classifier (among others), finetuning is carried out in a supervised way, since it requires data supervised by human labellers.
In case of Large Language Models, as they are trained with large amounts of open / available data, customize their answers to your needs is usually necessary.
There are many ways you can finetune a Large Language Model. One of the easiest options is the Trainer class from the transformers library, which has been used for quite some time now to finetune any kind of transformer-based model.
Recently, a new library called trl was released by Hugging Face to carry out the training of Reinforcement Learning by Human Feedback. One of the main steps of such a training is precisely Supervised Fine-tuning, so they made available a new class called SFTTrainer which manages the process by also providing parameter-efficient (peft ) and packing optimizations.
Want to know more?
If you want us to guide you through the process of Finetuning your Language Model, let us know at hi@mantisnlp.com

Supervised Fine-tuning: customizing LLMs was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.