
Text embedding models: how to choose the right one
Categories:
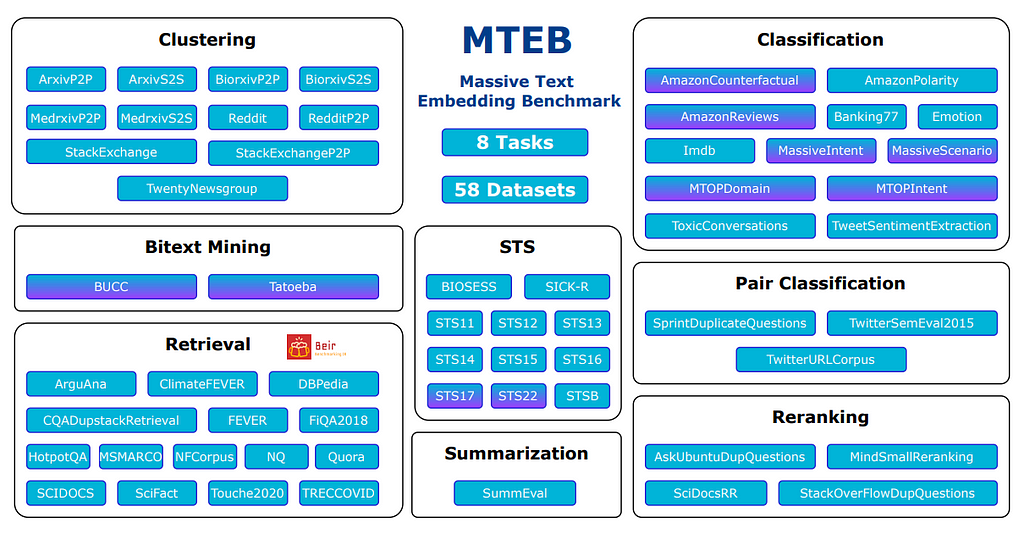
Overview of the Massive Text Embedding Benchmark (MTEB) | Source
What are embeddings and why are they useful?
Embeddings are fixed-length numerical representations of text that make it easy for computers to measure semantic relatedness between texts. They are the backbone of some essential NLP tasks, such as text similarity, semantic search, information retrieval and reranking, clustering, feature extraction for downstream tasks, and more recently, they are being used in the document retrieval step in retrieval-augmented generation applications.
Word embeddings vs. Text embeddings
Earlier embedding methods focused on obtaining word vectors and included neural network methods like word2vec and fastText, ML-based methods like GloVe as well as dimensionality reduction techniques like Latent Semantic Analysis (LSA). Although the methods differ, they all rely on the concept of similar words occurring together, for example, the learning objective of the skip-gram algorithm in word2vec is to predict words within a small context window given a word in the center.

The skip-gram model is trained to make target embeddings (‘apricot’) closer to (have a higher dot product with) context embeddings for nearby words (‘jam’) and further from (lower dot product with) context embeddings for noise words (‘Tolstoy’, ‘matrix’). | Source
The embedding of a text is then computed as an average of all word embeddings it consists of, and is essentially a distributed ‘bag-of-words’ representation. Although it goes beyond lexical similarity and is still a stable baseline for capturing topical similarity of texts, it fails to capture things like negation, word order, multiword expressions and idiomatic language and other contextual subtleties which makes it perform poorly on tasks requiring more nuanced understanding of text.
Transformer, the state-of-the-art architecture in NLP
State-of-the-art models in NLP are now overwhelmingly built with the Transformer architecture, where the mentioned shortcomings to a large extent are resolved. A Transformer model is essentially a feed-forward neural network consisting of stacked identical blocks. The original Transformer, designed for sequence-to-sequence tasks like machine translation, includes an encoder and a decoder — one to get a good representation of the context and the other to predict the target sequence with respect to both the context representation and already generated tokens, respectively. These two parts turned out to be quite useful on their own, with the BERT model family consisting of just the encoder and being used for discriminative tasks like text classification, named entity recognition (NER), etc. and the GPT family consisting of just the decoder and being used for generative tasks like text generation, summarization and more. Many text embedding models use just the encoder, with a few notable exceptions.
One of the main components that make Transformers so powerful is the attention mechanism inside each of the blocks, which captures every word’s interactions with every other word in a sequence, thus producing a word (or rather, token) embedding that is contextualized. That means that an embedding of a word is not static, but rather is altered by its context, for example, embeddings of the word ‘bank’ in strings ‘major enterprises are located on the right bank of the river’ and ‘acquisition of a major bank causes a stir’ would differ (as they should!). That, together with positional embeddings and the sheer scale of such models clearly has a lot of potential to encode the nuance of natural language. We refer the reader to this excellent blog post to get a better understanding of the inner workings of Transformers.

The attention mechanism helps to bake into the representation of the otherwise ambiguous word ‘it’ representations of the words ‘animal’ and ‘tired’, while in a model like word2vec the word ‘it’ would have likely been discarded as a stop word | Source
Text embeddings from Transformers, the naive way
While Transformer models like BERT quickly became the state-of-the-art for many supervised NLP tasks, using those pre-trained models to obtain useful text embeddings turned out to be trickier. The logical solution seemed to be, again, to average token activations of the last hidden layer in the network, or to use the special [CLS] token embedding that is trained to encode the entire input text. Packages quickly appeared that allowed to load and run a pre-trained, or even fine-tuned model with a few lines of code, such as pytorch-pretrained-bert (which evolved to be the transformers library, the point of reference for any Transformer-based model) and bert-as-a-service package. While the former had a stronger focus on facilitating fine-tuning and, in terms of obtaining text embeddings, only allowed to extract the final hidden states out-of-the-box, the latter offered multiple pooling strategies, such as mean pooling, max pooling, concatenation of several layers, first token [CLS], or last token [SEP]. After a systematic evaluation though, it was found, somewhat unexpectedly, that embeddings obtained from pre-trained Transformer models performed rather poorly on a range of textual similarity tasks, with mean GloVe embeddings significantly outperforming mean BERT embeddings.
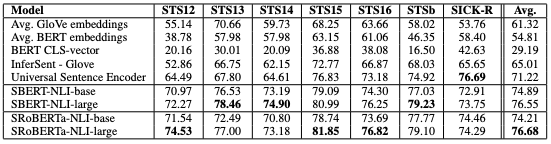
Performance (Spearman correlation) of different embedding models on text similarity tasks. | Source
Notably, in the original BERT paper, authors mention using either token embeddings from the second-to-last layer, or the concatenation of four last layers for their experiments training classifiers on fixed text embeddings. That can be explained by the fact that each layer in the Transformer architecture ends up capturing a certain aspect of input tokens, and the last layer learns to assist the pre-training tasks (MLM, NSP), failing to encode semantics of the sequence in a way that would enable measuring semantic relatedness of texts. Exactly which layer tends to encode which type of information is an interesting research question; this paper offers an investigation into that phenomenon.
Text embeddings from Transformers, the better way
To be clear, none of the above should be taken to mean that Transformers don’t produce useful representations — both the [CLS] token representation and the mean embeddings of the last layer are extremely powerful and are used in state-of-the-art NLP models. It is simply that a pre-trained Transformer model is a sort of a ‘generalist’ — it has learned a lot about how language works through self-supervised learning objectives on unlabeled texts, such as predicting a masked token in a sequence (BERT) or predicting the next token (GPT). To make it a ‘specialist’ in a certain task, one needs to fine-tune it on supervised data for that task and/or domain, such as classification, NER, question answering, dialogue, instruction following, etc.
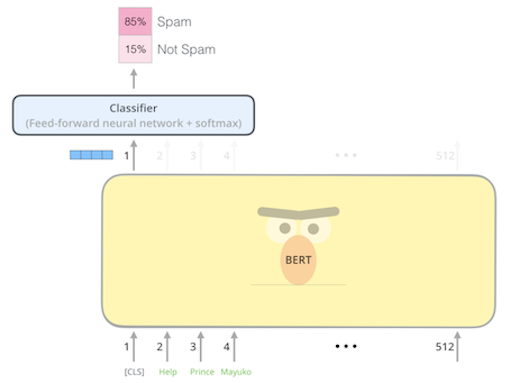
Fine-tuning BERT on sequence classification task. | Source
Thanks to this supervised fine-tuning step, both the task-specific layers (feed-forward classifier in blue in the picture above), and optionally some layers (all, or top n, or none) of the base BERT model (in yellow) are adjusted to perform well on the task while utilizing the general language knowledge learned during pre-training. For a more detailed overview of supervised fine-tuning and its powers, as well as practical examples, refer to our earlier post.
How do we then fine-tune a language model to output representations that are useful for comparing pairs of text? Note that we are interested in methods that map a single text into a fixed embedding so that we could, for instance, pre-encode texts and keep them in a vector store, only computing a new embedding for the query at inference. Also note that the concept of semantic relatedness of two texts that we are trying to capture is wider than the concept of semantic similarity: think of paraphrases (similarity) vs search query and a Wikipedia article (relatedness).
First of all, one needs a dataset explicitly indicating the degree of relatedness between paired texts, such as sentence-entailment (SBERT), post-comment (E5), docstring-function implementation (cpt-text). Secondly, to accommodate the paired nature of the data, such approaches typically use the siamese network architecture with triplet or contrastive loss, where the model consisting of two identical subnetworks with shared weights separately encodes texts, and is trained to minimize the distance between positive samples (texts in the pair) while maximizing distance between negative samples (usually texts from different pairs).
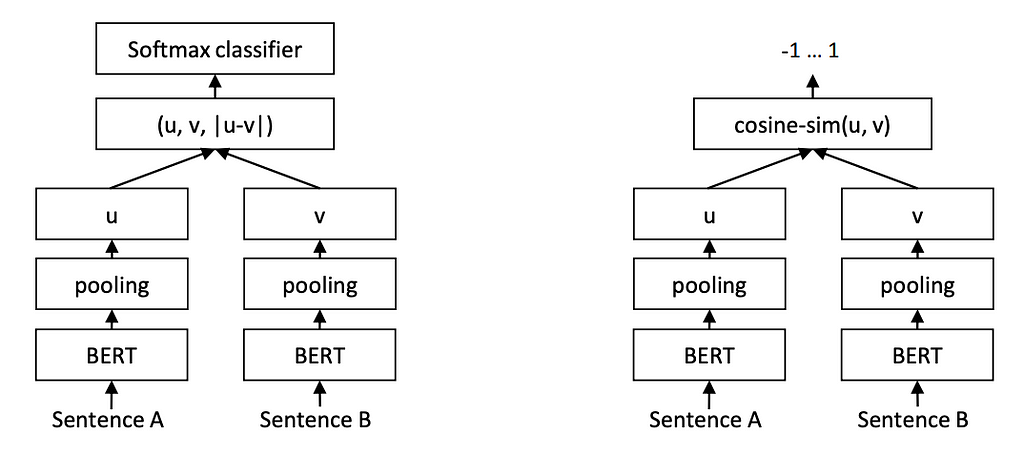
Siamese network architecture (SBERT) | Source
Although it is intuitive to use encoder models like BERT, decoder models like GPT have also been successfully used to obtain text embeddings. One example is cpt-text, which was proposed by OpenAI and claimed to have been used in the older versions of their Embeddings API. Due to the causal mask used by decoder models, it is the embedding of the last token [EOS] that is used as an embedding of the entire input sequence.
MTEB is a comprehensive benchmark for text embedding models
Even after fine-tuning an LLM to produce good embeddings for a certain task, it is not guaranteed that one gets similarly good performance when applying them to another task or domain. How do we know which model is a better choice for the particular use case? Is there a model that outputs universally good embeddings for multiple tasks? To solve the problem of fairly assessing models on various embedding tasks, the Massive Text Embedding Benchmark (MTEB) benchmark was recently proposed. It is a collection of 8 tasks, such as semantic text similarity, retrieval, clustering, reranking etc., containing dozens of datasets across multiple languages, with unified evaluation procedure and metric per task. It is constantly updated with both datasets and models, but it is clear that no one model can yet be called a truly universal embedding model — although there is ongoing research in that area.
It makes it easier then to make an informed decision about selecting an embedding model for a task at hand. Taking retrieval-augmented generation as an example, retrieving a chunk of a document most relevant to the query (prompt) corresponds to the task of asymmetric information retrieval. Looking at the Retrieval tab in MTEB and selecting the language of interest, we can see that the model available through OpenAI Embeddings API (shown as ‘text-embedding-ada-002’), which often pops up in tutorials, doesn’t actually look like a good choice for the task. At the time of writing, the leaderboard was topped by open-source models, such as GTE, E5 and BGE, that are available for commercial use, are just a couple GBs in size and produce smaller embeddings, potentially reducing latency of similarity computation. This way, MTEB can serve as a useful tool to help reduce costs and improve performance.
In sum, while choosing an embedding model for a particular use case, using one of many Transformer-based models fine-tuned for the specific target task an/or domain is likely going to be best, and the MTEB leaderboard is a great tool to assist with that, giving an idea of a model’s performance for a task or a group of tasks and a language, and featuring direct links to models in question.
Text embedding models: how to choose the right one was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.
