
Training, Fine-tuning, Augmenting Large Language Models: a Guide for Executives
Categories:
A Large Language Model (LLM) is an AI model that can understand and generate human language by learning patterns in vast amounts of data in the form of text. In this post, we will explore three key concepts related to LLMs: training, fine-tuning, and augmentation.
We’ll focus on how each approach utilizes text data, highlighting its impact on costs, and the value LLMs can deliver that can in turn impact your organization’s outcomes.
Training
Training is the process of creating an LLM from scratch by feeding it vast amounts of text data (Figure 1). During training, the model learns language patterns and develops an understanding of general knowledge. Once the training is complete, the LLM can function out-of-the-box, using its internal knowledge to understand instructions and generate responses.
In a lot of cases, the word “training” is used very loosely or it could be tempting to use it to describe any method that improves an LLM’s performance. It is fine to use it in a broader sense but it’s important to recognize the differences between the various approaches.
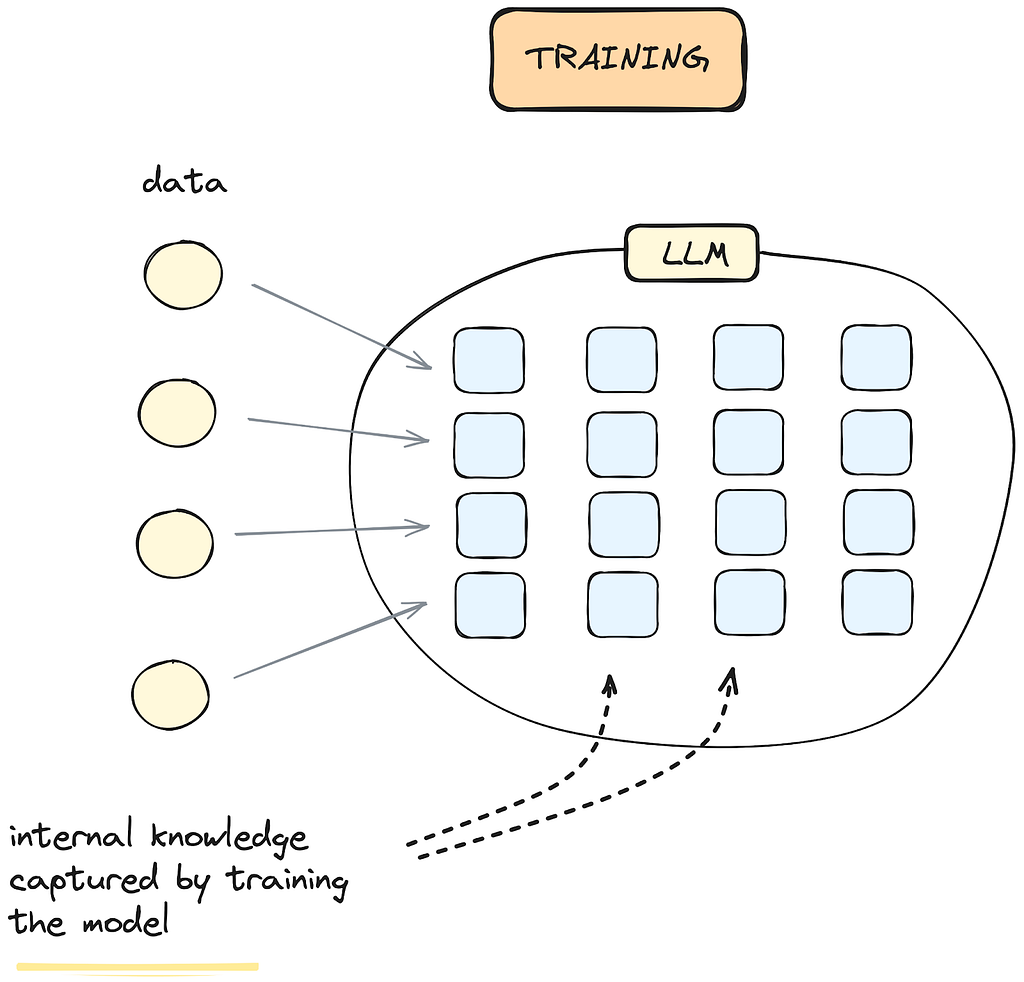
Figure 1. Training an LLM: Once the LLM is trained, it develops internal knowledge based on the data it was fed during the training process.
Once a model is trained, you can use it to solve tasks that you have identified in your organization and start delivering value. You can use it as-is, leveraging its internal knowledge. This approach is often straightforward and cost-effective, allowing you to tap into the model’s capabilities without significant additional investment in infrastructure or development.
One way to improve how an LLM solves a task at this stage is by refining the instructions you provide to the model, which are known as “prompts”. This process is known as prompt engineering and plays a crucial role in optimizing the model’s output.
If the model isn’t delivering the value you need, there are two popular and proven approaches to enhance its performance: fine-tuning or augmenting it.
Fine-tuning
Fine-tuning an LLM (Figure 2) is the process of refining a model’s internal knowledge by feeding it with domain-specific data. This can improve the model’s performance in solving tasks specific to your organization.
Domain-specific data refers to information that is unique and highly relevant for a particular industry or area of expertise. For example, in healthcare, it could be patient medical records and treatment guidelines and in customer support, this data could be support ticket data, chat transcripts, product manuals.
While fine-tuning has historically been a process of moderate cost, with recent advancements, fine-tuning has become more cost-effective.
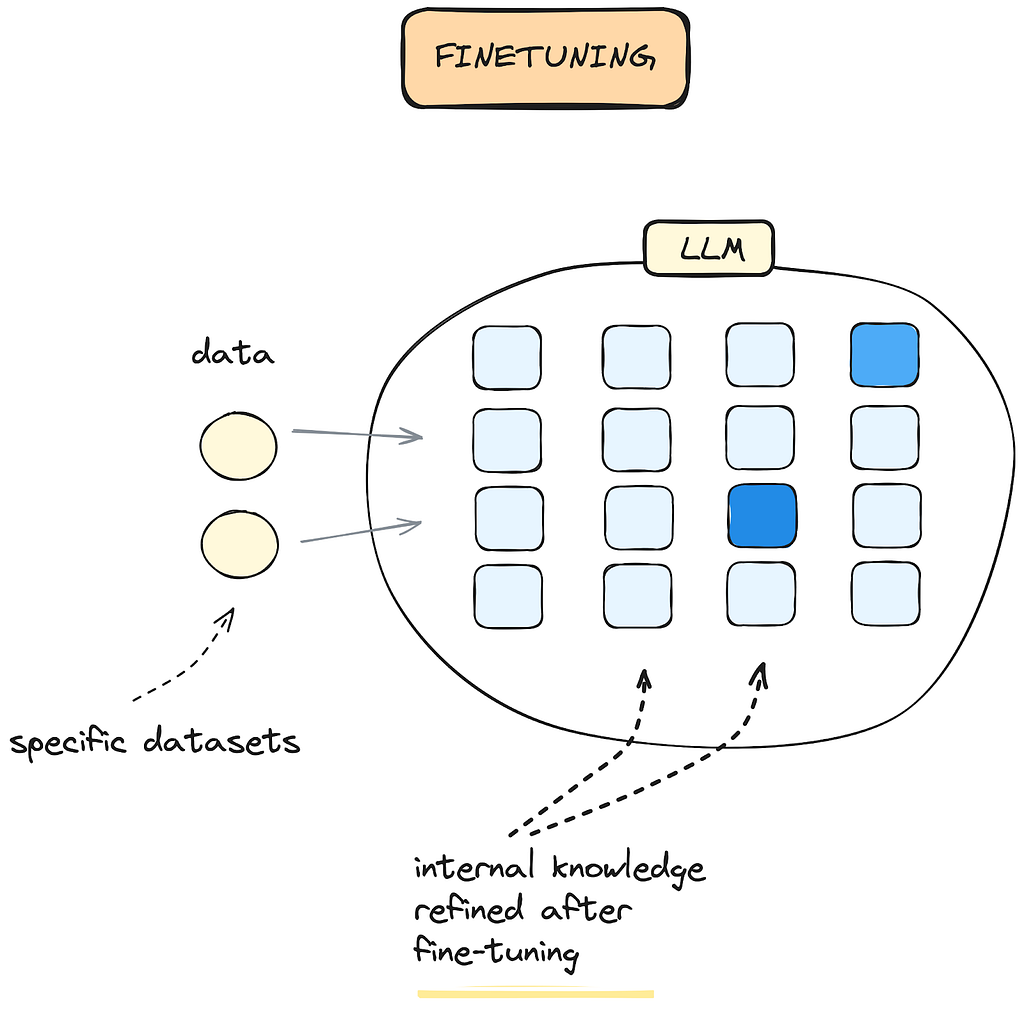
Figure 2. Fine-tuning an LLM: After fine-tuning using domain-specific data, the internal knowledge of the model is refined.
Augmentation
Augmenting an LLM is the process of combining its internal knowledge with external data sources (Figure 3) that can be useful for specific business needs. Like fine-tuning, it allows the model to deliver more value for specialized tasks, than using the model as-is.
While the model’s internal knowledge remains unchanged, it is now given access to external knowledge from which it can draw additional information. This can improve its ability to generate more precise answers. Both out-of-the-box LLMs, and fine tuned models can be augmented in this way.
This approach requires a moderate investment in development and infrastructure to integrate the external data sources.
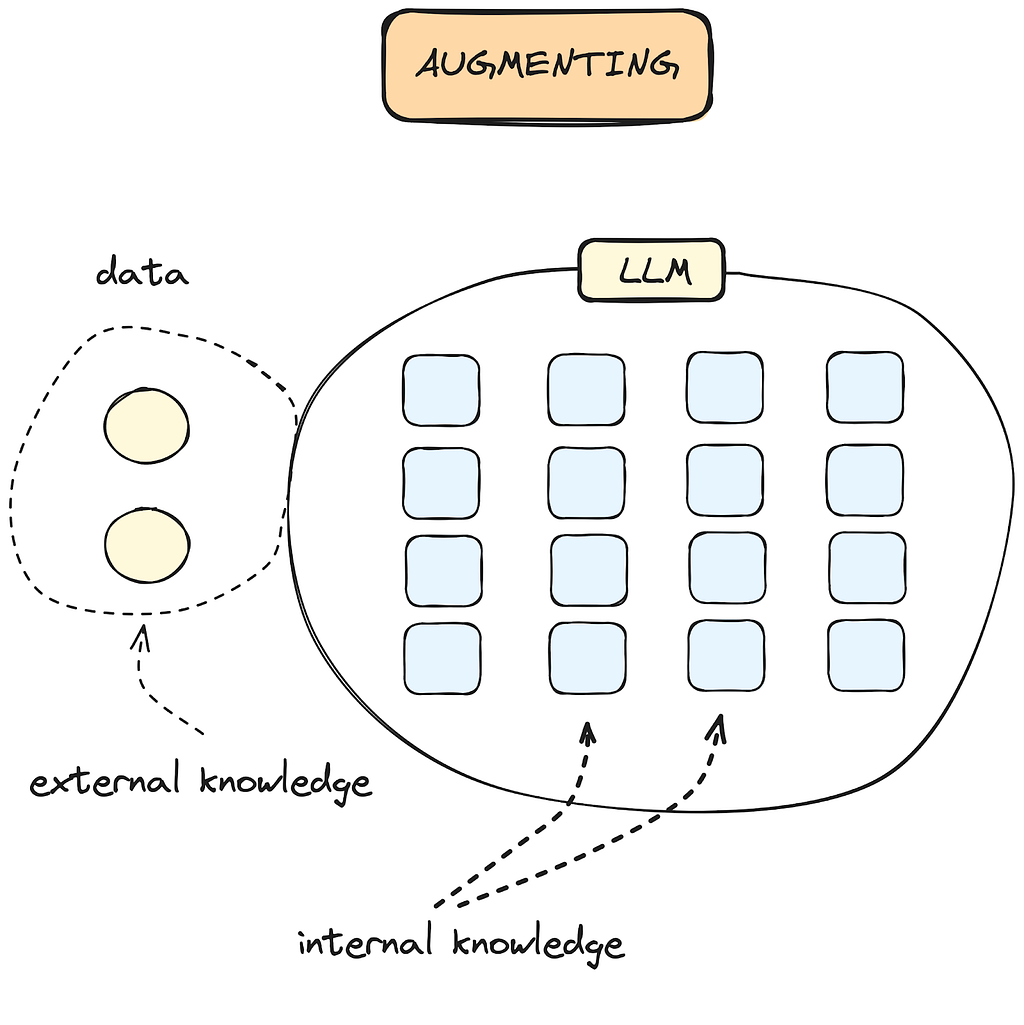
Figure 3. Augmenting an LLM: The LLM’s internal knowledge remains unaffected while it has access to external knowledge.
An example
A company’s customer support is entirely operated by human agents. Due to increasing demand, the team is struggling to handle the volume of enquiries, resulting in an average response time of 20 minutes and a customer satisfaction rate of 80%. To address this, the company plans to introduce chatbots as the first point of contact for customers.
Goal: Reduce average customer response time from 20 minutes to 5 minutes, while maintaining a 90%+ customer satisfaction score by the end of the quarter, by introducing chatbots as the first line of defense in customer support.
Step 1: Using an LLM as-is. The company implements an out-of-the-box LLM chatbot to handle basic customer enquiries, such as FAQs, order tracking, and troubleshooting. Human agents are reserved for more complex queries.
- Outcome: The chatbot reduces the load on human agents, dropping the average response time to 12 minutes and slightly improving the customer satisfaction rate to 85%. While this is an improvement, it’s still far from the executive’s goal of 5 minutes and 90%+ satisfaction.
Step 2: Augmenting the LLM. To further improve, the company augments the chatbot by integrating it with external data sources, including product information databases, the company’s knowledge base, and CRM. This gives the chatbot access to real-time data and more accurate answers.
- Outcome: Average response time drops to 8 minutes, and customer satisfaction rises to 88%. The chatbot is better at resolving enquiries without passing customers to human agents. However, more complex questions still require human intervention, preventing the company from hitting its target.
Step 3: Fine-tuning the LLM. The company fine-tunes the chatbot using domain-specific customer support data, such as previous enquiries and responses from human agents. This helps the chatbot better understand the specific challenges and language of the company’s customer base.
- Outcome: After fine-tuning, the chatbot handles more complex queries effectively. The average response time decreases to 5 minutes, and customer satisfaction reaches 91%, meeting the executive’s goal. Human agents now primarily handle only highly complex or sensitive cases.
Step 4: Augmenting the fine-Tuned LLM: To maximize performance, the company augments the fine-tuned chatbot with the external data sources previously integrated. This ensures the chatbot can continue to provide real-time, accurate information and handle both simple and complex queries effectively.
- Outcome: The fine-tuned and augmented chatbot consistently maintains a 5-minute response time with a 93% customer satisfaction rate. The company successfully reduces the load on human agents, allowing them to focus on critical cases, while the chatbot handles the majority of customer enquiries.
Following the example above, the figure below describes the “journey” of an LLM in enhancing business outcomes.
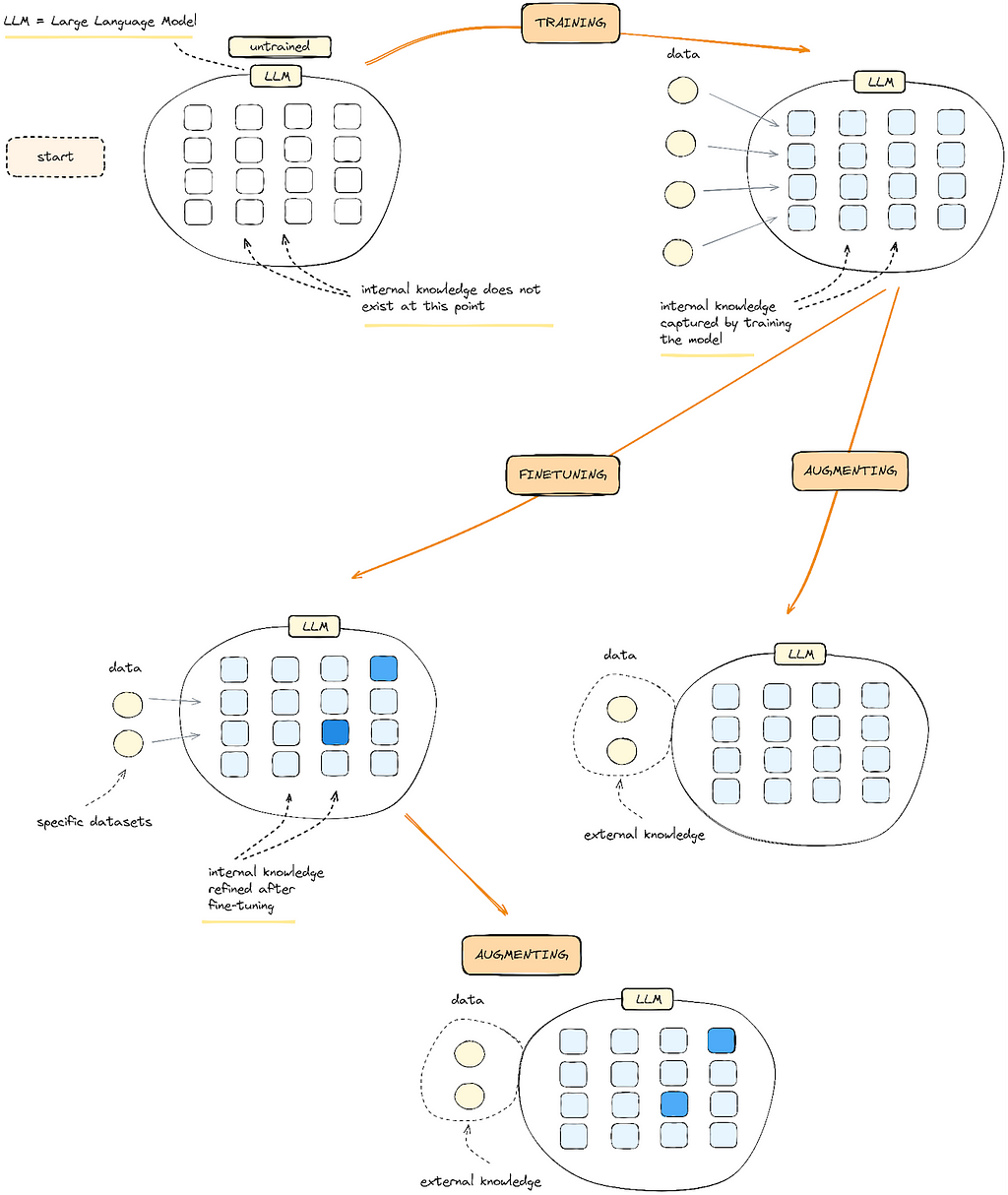
Figure 4: A “journey” of an LLM: starting from an untrained model, training it with data (text) to acquire internal knowledge, fine-tuning it to refine its internal knowledge and augmenting it to give it access to external knowledge.
Costs, Data, Maintenance, Performance
Here is a summary on the costs, data considerations, maintenance and potential performance improvement that can help inform your decision in picking the right method for using an LLM.
Costs
Training: High costs — Ranging from tens of thousands to several millions of dollars, depending on the size and complexity of the model.
Fine-tuning: Low to medium costs — From hundreds to hundreds of thousands of dollars, depending on the scale and requirements of fine-tuning.
Augmentation: Low cost — Typically between hundreds and thousands of dollars.
Data Considerations
Training: Requires massive and diverse datasets (hard to get)
Fine-tuning: Requires relevant, domain-specific data (easy to get)
Augmentation: Requires relevant, domain-specific data, curated in external knowledge bases
Maintenance
Training: High — Requires retraining in order to update to the latest information
Fine-tuning: Low-medium — Requires fine-tuning in frequent time intervals to update to the latest information
Augmentation: Low — Requires continuous curation of the knowledge base, to make sure it contains up-to-date information. It is more flexible and dynamic than fine-tuning: once the external database is updated, it can readily consume this knowledge
Potential performance improvement
Training: Might have issues solving domain-specific tasks, out-of-the-box models come with knowledge cut-offs, and are updated every some months. Even if they are updated, specific domain knowledge information does not exist in the out-of-the-box model.
Fine-tuning: Can solve domain-specific tasks within a well defined field, where real-time access to fresh knowledge is not a strict requirement.
Augmentation: Can solve domain-specific tasks, with real-time access to fresh knowledge.
Conclusion
Training, fine-tuning, and augmenting Large Language Models (LLMs) each offer distinct approaches to improving an AI model’s performance based on your needs.
Training requires vast amounts of data and resources and it is in general costly and time-consuming.
Fine-tuning uses domain-specific data to refine an existing model’s responses, by altering the model’s internal knowledge. The cost to fine-tune a model depends on the level of fine-tuning, but it is much more cost-effective than training it.
Finally, augmentation allows a model to access external knowledge. A model can be augmented after training and after fine-tuning.
Training, Fine-tuning, Augmenting Large Language Models: a Guide for Executives was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.
