Automatic Prompt Engineering (Part III: Hands-on: Knowledge Retrieval)
Categories:
This is the continuation of Automatic Prompt Engineering (APE) for Retrieval-Augmented Generative Models, where we discussed the main concepts and what the main papers say about Automatic Prompt Engineering Workflows. Also, we picked up RAGs (Retrieval-Augmented Generative Models) as our target use case where APE will be applied. Before continuing with this hands-on blog post, we highly recommend taking a look at the previous posts of this series: Part I and Part II.
In Parts III and IV we are going to share Python code snippets leveraging OpenAI API, Langchain , FAISS as a Vector Store and a rule-based evaluation module, to implement an APE workflow.
We have divided the workflow in a series of 12 small steps. In Part III we will be covering the Knowledge Retrieval Part and Knowledge Integration, leaving Evaluation for Part IV. If you are interested in seeing all the other mentioned approaches in action, contact us at hi@mantisnlp.com.
1. We start with a small VectorStore with some populated knowledge.
These are the Python definitions of the VectorStore class we are going to use for Knowledge Retrieval. Don’t forget to import FAISS and OpenAI from Langchain!
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
class VectorStore:
def init(self):
self.db = None
self.embeddings = OpenAIEmbeddings()
def index_array(self, knowledge, refresh=False):
logging.info(“Generating embeddings with OpenAI…")
self.db = FAISS.from_texts(knowledge, self.embeddings)
logging.info(f"Saving embeddings in FAISS into {config.STORE_PATH}")
self.db.save_local(config.STORE_PATH)
In this example, we store our pieces of knowledge. We used those proposed in the Generated Knowledge Prompting for Commonsense Reasoning paper:
> Greece is approximately 131,957 sq km, while Mexico is approximately 1,964,375 sq km, making Mexico 1,389% larger than Greece.
> Condensation occurs on eyeglass lenses when water vapor from your sweat, breath, and ambient humidity lands on a cold surface, cools, and then changes into tiny drops of liquid, forming a film that you see as fog. Your lenses will be relatively cool compared to your breath,especially when the outside air is cold.
> Fish are more intelligent than they appear. In many areas, such as memory, their cognitive powers match or exceed those of ’higher’ vertebrates including non-human primates. Fish’s long-term memories help them keep track of complex social relationships.
> Those who consistently averaged less than one cigarette per day over their lifetime had nine times the risk of dying from lung cancer than never smokers. Among people who smoked between one and 10 cigarettes per day, the risk of dying from lung cancer was nearly 12 times higher than that of never smokers.
> A pebble is a clast of rock with a particle size of 4 to 64 millimeters based on the Udden-Wentworth scale of sedimentology. Pebbles are generally considered larger than granules (2 to 4 millimeters diameter) and smaller than cobbles (64 to 256 millimeters diameter).
NOTE: Another alternative would be to use LLMs as generation mechanisms to get some data to fill your templates, instead of using the RAG.
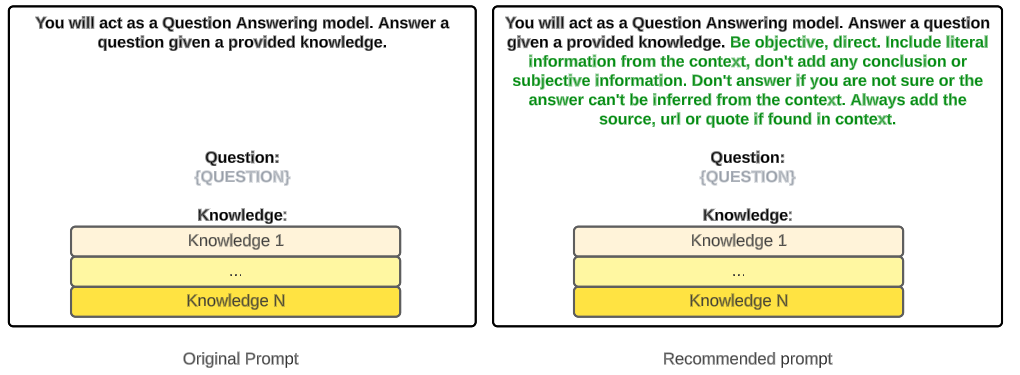
2. We create our prompt to be tested.
This is the prompt we will be testing (and trying to improve):
You will act as a Question Answering model. Answer a question given the provided knowledge.
Question: {question}
Knowledge:{knowledge}
In question we will have all the questions we are going to test. And in knowledge, the pieces of knowledge I have in my Vector Store, relevant to them.
3. We define a series of questions who will help us, all along with the Knowledge, to evaluate the prompt.
We will use a list of questions, which will retrieve pieces of knowledge from our Vector Store. For each of them, we will get the metrics so that we can evaluate how good is the prompt we have defined.
The knowledge is what we have in the Vector Store, defined in the previous point. The questions are the following:
questions = [
“A common effect of smoking lots of cigarettes in one’s lifetime is a higher than normal chance of getting lung cancer.”,
“A rock is the same size as a pebble.”,
“A fish is capable of thinking.”,
“Glasses always fog up”
]
4. We carry out Knowledge Retrieval.
For each question Q, we retrieve pieces of Knowledge: K1..Kn.
QUESTION: A common effect of smoking lots of cigarettes in one’s lifetime is a higher than normal chance of getting lung cancer.
KNOWLEDGE RETRIEVED
> [0.2455301433801651]: Those who consistently averaged less than one cigarette per day over their lifetime had nine times the risk …
>[0.4512312441231234]: Condensation occurs on eyeglass lenses when water vapor from your sweat, breath,
>[0.5511421551975171]: Fish are more intelligent than they appear. In many areas, such as memory, their
>[0.5881238123919231]: File corruption or missing files (F205) can lead to errors within applications…
This is done with a simple line of code thanks to Langchain — FAISS integration.
def knowledge_retrieval(self, question):
return self.db.similarity_search_with_score(question)
5. We discard non relevant knowledge and combine the relevant information.
Some pieces of knowledge will not be relevant enough to be included in the answer. We remove them using a similarity threshold.
QUESTION: A common effect of smoking lots of cigarettes in one’s lifetime is a higher than normal chance of getting lung cancer.
KNOWLEDGE RETRIEVED
[0.2455301433801651]: Those who consistently averaged less than one cigarette per day over their lifetime had nine times the risk …
[DISCARDED]: Condensation occurs on eyeglass lenses when water vapor from your sweat, breath,
[DISCARDED]: Fish are more intelligent than they appear. In many areas, such as memory, their
[DISCARDED]: File corruption or missing files (F205) can lead to errors within applications…
COMBINED KNOWLEDGE:
Those who consistently averaged less than one cigarette per day over their lifetime had nine times the risk of dying from lung cancer than never smokers. Among people who smoked between one and…
This can be easily done thanks to the scores returned in point 3, function similarity_search_with_score:
for r in res:
if r[1] < THRESHOLD:
knowledge_elements.append(r[0].page_content)
Here, r is a tuple having the text in r[0] and the score in r[1]. THRESHOLD is our similarity threshold. The smaller the better. We usually set it to around 0.25.
6. We carry out Knowledge Integration.
We already have:
- Our question(s) Q;
- Our combined knowledge K, relevant to the question, obtained from the Vector Store;
What we are looking for is an answer A, which answers to Q given K.
class KnowledgeIntegrator:
def init(self, model_name, temperature):
self.llm = ChatOpenAI(model_name=model_name, temperature=temperature)
def get_answer(self, prompt, params):
llm_chain = LLMChain(
llm=self.llm,
prompt=PromptTemplate.from_template(prompt)
)
with get_openai_callback() as cb:
result = llm_chain(params)
costs = cb
return result, {‘total_cost’: costs.total_cost}
We will use a temperature=0 and to remain as loyal as possible to the context. Our model is gpt-3.5-turbo-0613.
We also included a small snippet to return not only the result, but the cost (expenses) of the call to OpenAI API.
7. We get the answer.
Now we just send the question Q and the combined knowledge K’ to the LLM to get an answer we will use to evaluate the prompt on.
QUESTION: A common effect of smoking lots of cigarettes in one’s lifetime is a higher than normal chance of getting lung cancer.
COMBINED KNOWLEDGE:
Those who consistently averaged less than one cigarette per day over their lifetime had nine times the risk of dying from lung cancer than never smokers. Among people who smoked between one and…
ANSWER»
Yes, the common effect of smoking lots of cigarettes in one’s lifetime is a higher than normal chance of getting lung cancer. The provided knowledge states that even those who consistently averaged…
This is achieved just by calling to get_answer method as follows:
knowledge_retriever = KnowledgeRetrieval(config.knowledge)
knowledge_integrator = KnowledgeIntegrator(model_name=‘gpt-3.5-turbo-0613’, temperature=0)
for question in config.questions:
KNOWLEDGE RETRIEVAL: I retrieve the best pieces of knowledge given my question
knowledge = knowledge_retriever.retrieve(question)
KNOWLEDGE INTEGRATION: I combine question with the knowledge and create and answer
answer = knowledge_integrator.get_answer(config.PROMPT_TEMPLATE,
{‘question’: question, ‘knowledge’: knowledge})
At this point, we are able to get answers A from questions Q given a knowledge K. Now, we need to evaluate. We share the evaluation module of our APE workflow in the Part IV of our blog post series.
In this third blog post, we have covered the first 7 steps and provided some code snippets showcasing the creation of a prompt template to ask questions, using Knowledge Retrieval to get pieces of knowledge, and Integrating those with a Knowledge Integration technique.
In the last post of the series (IV) we will show how to carry out Evaluation and feedback your prompts in an scalable and reusable way.
Want to know more?
I hope you enjoyed this post. Remember this is a series of 4 posts and it has a continuation. Make sure you read them in a sequential order, starting from Part I and Part II.
If you need help in your NLP processes, MantisNLP will be glad to help! Feel free to reach out at hi@mantisnlp.com and stay tuned for more blog posts!

Automatic Prompt Engineering (Part III: Hands-on: Knowledge Retrieval) was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.