
How we think about Generative AI
Categories:

Thinking about Generative AI. Created using Dall E 3
It’s no exaggeration to say that the world has changed in the last year thanks to the developments in Generative Artificial Intelligence (AI). Models such as GPT3 and Dall・E 2 changed our expectations about what was possible from AI, much faster than anticipated by experts in the field (such as Geoffrey Hinton).
At Mantis, we’ve seen a lot of requests from clients, old and new, about how they should be using Generative AI such as Large Language Models (LLMs) like ChatGPT. We’re in the privileged position of having spoken to lots of companies about how they are making use of LLMs, and we’re helping a number of organizations to map out their strategy for how to integrate LLMs into their businesses.
This is the first in a series of blogs that describes our current thinking about LLMs based on our experience working with clients over the last year. This first post is about when we should use them, and what a typical LLM journey looks like for us — so far!
When should you not use an LLM?
Recent developments have put cutting edge models in the hands of anyone with an internet connection, and this has sparked many people’s imaginations about the ways that AI can be applied to their business.
Quite often however, we find ourselves counseling against using LLMs for a number of use cases because there are cheaper, faster, and better performing alternatives. When all you have is a model like ChatGPT, all problems start to look like LLM problems, even if it is the computational equivalent of hammering a nail with a very costly microscope.

When all you have is an LLM, all problems look like LLM problems. Even if this is the computational equivalent of hammering a nail with a costly microscope. Created using Dall E 3.
LLMs are huge models that are relatively expensive, slow, and can have a large environmental footprint. There are also some disadvantages to relying on LLMs provided by third parties related to the reliability and stability of these models, for example it is well documented that the performance of models such as GPT3.5 and 4 changes over time, and this is something over which you will have little control.
Consequently, there are a subset of tasks for which you probably shouldn’t use an LLM in a business critical application (if you’re prototyping, it’s a different story: see below). These include tasks such as sentiment analysis, text classification, and Named Entity Recognition (NER) for which high performing, smaller models existed before the arrival of LLMs. These problems are well structured, extractive AI tasks that smaller models can do really well, and given the right data will outperform an LLM in speed, cost, reliability, and performance.
When should you use an LLM?
We think that there are two concrete use cases for which LLMs are ideal.
Prototyping
LLMs are ideal for prototyping. That is, quickly testing an idea that would traditionally have required:
- AI development expertise
- Relevant data to train a model
- Time
LLMs are able to do so-called: zero and few-shot prediction: meaning that they are able to produce an output with either no, or few, examples of what you would like the output to be. This includes extractive AI tasks for which we would expect smaller, more specialist models to perform better.
LLMs are a great way to get started, prove a use case with minimum development time, and then help you to transition to a smaller, better, more specialist model for a production use case (more on this later).
True Generative use cases
True to the name Generative AI, LLMs excel at producing high quality text outputs. LLMs are unparalleled for use cases such as content generation (e.g. copywriting, or writing research grants), and summarisation, whilst anyone who has used ChatGPT will have seen that LLMs can also power impressively human-sounding chatbots.
In recent months, particular interest has built around chatbots and assistants — and more generically Question-Answering systems that are powered by Retrieval Augmented Generation (RAG) systems, utilizing LLMs. We’ve posted about RAG systems before and even produced a demonstration using the content from the UK Government’s website GOV.UK. These RAG systems allow for the latest information to be made available to the model, and can also help to reduce one of the most important failure modes of LLMs: hallucinations.
Another impressive use case that we have seen in recent weeks, at which LLMs do very well, is for reviewing, for example as part of the scientific peer review process. Whilst LLMs are unlikely to fully replace human reviewers in this highly technical field, they can provide helpful suggestions to human reviewers around topics such as clarity of presentation.
The LLM Journey
OK, so you’ve decided you are going to use an LLM, now what’s the journey to getting the performance you want? Here we outline the steps we take to tuning LLM performance.
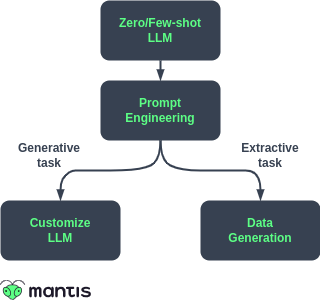
Zero-shot and Few-shot prediction
We’ve touched already on the use of LLMs for zero and few shot prediction. Our first steps are simply to prompt the LLM to produce the output we want: a so-called zero-shot prompt, meaning that the model doesn’t see in advance an example of what you want it to output.
If we don’t get the performance we want, we can likely improve performance by providing the model with a few examples of what we want: so called few-shot prediction. This is a simple step that can be implemented very easily.
Prompt optimisation
The quality of the prompt can greatly affect the quality of the output of an LLM, and so if you want to improve the performance of the LLM, you should spend some time optimizing the prompt. Ideally you would set up an automated way of evaluating the effect of manual changes to your prompt (see some examples in our blog), or better still: automate the entire process of improving the prompt. This process, called Automated Prompt Engineering (APE), is the subject of another of our blog series, in which we outline how you can implement this kind of system.
Data generation
If the use case is not generative, and up until now we’ve been using an LLM for prototyping, this is when we’d look to transition to a smaller, more performant model. We’ll need data to train these models on data, but LLMs can help us in two ways.
Firstly, we can ask an LLM to annotate real data that we already have, but that has not been annotated yet. Even if we don’t fully trust the model’s annotations, it may be much faster to annotate with an LLM, and then have a human correct the annotations (or a subset of them) rather than relying totally on human annotators.
In some cases we can rely on the model to generate entirely synthetic data, with or without labels. Again, this may need some human intervention to ensure quality, or at the very least evaluation.
Once we have sufficient data, we can train a smaller model for example using SetFit or a custom transformer model if we have more data available (see our recipe for this approach). We can then involve the LLM in an iterative process of improving the data, and retraining the model, perhaps incorporating the LLM into an active learning process, so that we can iteratively improve the quality of the training data.
Be aware though that some LLMs have licenses which prohibit their use for data generation in this way.
Customizing the LLM
The last step in the journey is to customize the LLM itself. There’s a couple of ways that we might do this.
The first is through a process called supervised fine tuning (SFT), where we continue to train (fine tune) the model with data from our domain of interest. Generic LLMs are trained on a wide variety of text sources (such as Wikipedia, Reddit, etc.), but for fine tuning we would choose text specific to our domain of interest, such as finance: for example BloombergGPT: a model fine tuned specifically for the finance domain.
Another option is to tune the model to align better to our preferences. There are a number of ways we might do this: for instance we can ask the model to generate a response to a query multiple times, and then pick our favorite response (Direct Preference Optimisation). Another approach is to train a second model to recognise the kind of responses that we prefer, and then use this model to adjust the outputs of the LLM, so-called: Reinforcement Learning through Human Feedback (RLHF).
This step makes sense when we want to adjust the tone of voice in a chat application (and prompt engineering was not enough), or if we want the model to follow instructions or perform better on our task. We leave this step until last because it is also the most expensive and time consuming, and requires us to have data with which to fine tune the model.
We’ve published a series of four blog posts on the topic of supervised fine tuning with our friends at Argilla, the first of which you can find here.
Next time…
In this article we’ve outlined our thinking about when you should use an LLM, and our approach to tuning the performance of the LLM. In the next post in this series, we’ll introduce the LLM pyramid which describes our thinking about the capabilities of large and small models, both proprietary and open source, to help answer a very common question we receive: should you use a proprietary LLM or an open source one.
As ever, if anything I’ve talked about here chimes with what you’re doing in your organisation and you’d like to get some help with your Generative AI journey, please feel free to reach out to us at hi@mantisnlp.com.
How we think about Generative AI was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.
