
How we’re thinking about Generative AI: Proprietary vs Open Source
Categories:

Caption: Thinking deeply about Large Language Models. Produced by DallᐧE 3
In the second part of our series about Generative AI (you find the first post here), we’re looking at the difference between proprietary and open source Large Language Models (LLMs), and under which circumstances it makes sense to choose one over the other. This is something that we’re frequently being asked by clients, and this post represents some of our current thinking.
Some caveats
More so than with part I, we need to caveat everything in this post with the warning that things are moving really really fast, so this post represents our thinking today, but we fully expect it may be outdated tomorrow (in fact we’ve needed to rewrite parts of it multiple times since we wrote the first draft).
The other caveat worth stating is that the only way to access proprietary LLMs is via API, and we’re really comparing apples with oranges by comparing proprietary APIs with open source models. That’s because we don’t really know what is going on behind the proprietary model APIs. We don’t know if we are getting a response from a single model or many models, nor do we know about the post-processing steps or guard rails that are in place.
With open source models that you manage yourself it’s a lot more transparent, we’re getting the ‘warts and all’ output from the model, with all that that implies. Nonetheless, in this blog post, I will refer to the proprietary APIs as models, just to make the text easier to follow.
It’s also worth thinking about what open source actually means. Many of the models we lazily refer to as open source in this post are not truly open source in the sense that they, and the data on which they were trained, are published under a permissive Apache, MIT, or GPL licence. If you’re going to work with these models, you need to understand the licences under which they are published, and the implications that this has for your specific use case.
Finally, the eagle-eyed amongst you will notice the conspicuous absence of a key class of models, namely: phi, Vicuna, Alpaca, WizardLM, and Orca. We’ve deliberately not included these models because they exist in somewhat of a grey area, having been trained on data produced by a large proprietary model (usually GPT4).
With all that said, let’s dive in.
tldr;
As we mentioned in our last post, our position is broadly the following: if you’re prototyping or you want best in class performance, then it probably makes sense to use a proprietary model through an API. If you want control or customisability then it probably makes sense to use an open source model deployed in an environment of your choice.
That being said, let’s step through a series of concerns that frequently come up when we talk to clients about LLMs, and then we’ll dive deeper into more specific models across the proprietary and open source landscapes.
Performance
If your number one concern is that the model provides the absolute cutting edge performance — in terms of how well the model solves your problem — and nothing else will do, then you should use a proprietary model API.
We’ll discuss the relative performance of different models later, but the short answer is that — so far — open source models have not matched the performance of the largest proprietary models, and nor are they likely to in the near future.
Stability and Reliability
Using a proprietary model API you have very few levers to ensure that the model you are using is stable and reliable. As with any third party service, you basically need to accept the capabilities of the API from the provider, and whilst these capabilities are constantly improving, using popular proprietary APIs can be subject to large variations in latency and periods of degraded performance or outages. You may also not have complete flexibility over which version of a model you are using and when that version changes.
If you are building the model for a production use case for which stability and reliability are critical, then it may make sense to use an open source model. You’ll then be in control of the amount of computing resources available to the system, and you’ll be able to optimise this to ensure a balance of cost and stability.
You’ll also be in control of the level of redundancy that you build into the system to ensure that the service is as reliable as it needs to be. None of this is without cost, but for now at least, if you want complete control over these aspects of a deployment, the only way is for you to deploy an open source model in a computing environment of your choice.
Inference Speed
Similar to stability and reliability, when using a proprietary API you need to accept the inference speed as a given; there are no levers for you to pull.
With an open source deployment you can decide how much computing power to allocate — you can scale up or down your GPU size, or bring new devices online to handle the load across the system and optimise the model’s inference speed (and cost) for your use case.
Privacy, Security, and Intellectual Property
If your organisation is particularly concerned about the privacy of your users, the security of your data, and the sensitivity of your intellectual property, an open source solution deployed in an environment which you totally control probably makes sense.
In time, as LLMs become more commoditised it’s likely that we will all come to trust third party providers with our data just as many organisations trust cloud service providers with their data now. But, there will always be a subset of organisations for whom guarantees of third party providers are not enough, and will want to host their own models in their own environment — and in this case an open source deployment makes sense.
Models
The landscape of models is confusing — let’s be honest. There are hundreds of models out there, and more being released each week. It’s a wilderness of Llamas, Vicunas, Alpacas, Falcons, Beagles… and it helps to try to break down this complexity down into something more manageable.
The way we tend to describe the landscape is like a pyramid with a few really high performing models at the top like GPT-4, and the more traditional language models (small by today’s standards) like BERT at the base of the pyramid. For conceptual simplicity, we split the pyramid into four layers which we’ll describe in turn.
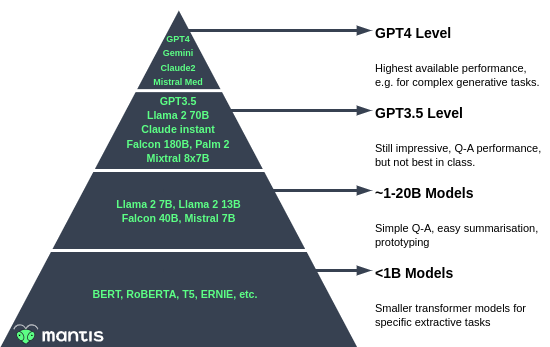
The LLM pyramid, our conceptual model for thinking about Large Language Models.
“Pinnacle” (GPT4 level) models
The top of the pyramid is dominated by a few proprietary models: OpenAI’s GPT4, Anthropic’s Claude, Google’s Gemini2 and the new Mistral Medium which has recently shown impressive performance on popular benchmarks such as the LMSys chatbot arena.
We don’t try to define what these models are capable of here, but it’s worth looking at the respective homepages for lots of examples of what these impressive models can do (https://openai.com/gpt-4, https://deepmind.google/technologies/gemini/#hands-on, https://www.anthropic.com/news/introducing-claude). Bubeck et al (2023) also give a very thorough deep dive into an early version of GPT4 in Sparks of Artificial General Intelligence: Early experiments with GPT-4, and for a hands-on approach to getting a feel for these models you should experiment with the LMSys chatbot arena.
If you need best in class performance on complicated tasks, then these are the models you should be using, and as of now: all are proprietary.
Mid (GPT3.5) level models
The next group of models we loosely call the GPT3.5 level group. This is the current default model in use on ChatGPT, so its capabilities are likely to be familiar to many. This group includes a mix of proprietary and open source models, such as:
- GPT3.5 (proprietary, 175B?)
- Mixtral 8x7B (open source, 8x7B)
- Llama2 (open source, 70B)
- Palm 2 (proprietary, 340B)
- Claude Instant (proprietary, >130B?)
- Falcon (open source, 180B)
These models all produce impressive results, and are excellent for a range of generative applications such as Question-Answering and summarisation, as well as producing high quality zero and few shot performance on extractive tasks such as text classification and NER.
If you have any of the concerns that we discussed previously such as privacy security, or IP protection, or want to have fine grained control over stability, latency, cost, and performance, but don’t need best in class performance, then one of the open source models from this layer in the pyramid may be a good option.
Lower performance models (~1–20B)
After the mid group, there exists a large pool of mostly open models that are suitable for specific use cases, but lack the general applicability of the mid and high performance models.
These models are good for simple generative use cases, for example easy summarisation where less nuance is required, or Question-Answering over generic topics. These models may also be good candidates for prototyping: to prove out a use case before moving on to a larger more costly model. These models have also shown excellent performance when fine tuned for the specific use case. We’re thinking primary here of:
- LLAMA2 7–13B
- Mistral 7B
- Smaller proprietary models from Google (Gemini Nano), etc.
The motivations for using these models are several, but may include: infrastructure size constraints, inference speed, or compute cost.
Another motivation may be specificity; for example the IGEL family which is a family of models fine tuned specifically for the German language.
Small(!) models
Finally, we have the language models which are no longer considered to be ‘large’, and are much more uniformly open source. Here we’re thinking of smaller transformer models such as BERT and its many variations like RoBERTA.
These models perform very well on well structured (extractive) problems for which there are a lot of annotated data. These open source models excel where size, speed, and cost are a concern. They also overcome the stability and privacy concerns, as we can easily train or fine tune our own models and deploy them wherever they need to be deployed.
It’s these models that we were referring to in the first part of this series when we talked about using LLMs to generate data to train smaller transformer models.
Summing up
In this post we’ve outlined the way we think about the landscape of open and proprietary LLM models. It’s not perfect, but it helps us to frame the conversation with clients around the various capabilities of different models, and whether those models should be proprietary or open source.
We’d love to hear if you’ve found this post helpful or if you disagree! Please reach out to us in the comments below. Equally, if you’re trying to make sense of how your organisation should make use of LLMs, we may be able to help. This kind of strategic LLM consultancy is our fastest growing type of client engagement.
We’re also working on a series of workshops for decision makers and technical experts. We’ll make an announcement about this in the coming weeks, but if this sounds interesting in the meantime, check out the landing page or reach out to us at hi@mantisnlp.com.
In the last blog in this series, we’ll talk about the trends that we see in the development of LLMs and how these trends are once again changing the way we think about space. Stay tuned!
How we’re thinking about Generative AI: Proprietary vs Open Source was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.