Prompt Engineering — Part III — Examples of prompt construction
Categories:
Prompt Engineering — Part III — Examples of prompt construction
In the last blog from our series, we covered how to construct a prompt for Large Language Models (LLMs). In this blog we’ll look at some concrete examples of prompts and how much they can affect results.
Text-Classification
Let’s start with a text classification problem. We will use the emotions sections from the tweet_eval dataset. The task is to classify a tweet in one of four possible emotions, anger, joy, optimism, sadness
In all the experiments, we try to start from a very basic prompt and then iterate over it trying to improve it by targeting specific things. We have 5 prompts for each task.
This is our first prompt. We also saw it in the prompt structure section.
The bits that you see between {} are placeholders for the input text. For example {text-n-shot} will be the text of each n examples we select. Together with {label-n-shot} which is the result for each. While the {current_text} is the text we currently want to label.
Classify into 4 labels: anger, joy, optimism, sadness
Text: {text-n-shot}
Label: {label-n-shot}
…
Text: {current_text}
Label:
The newlines present here are an important factor also by the way. The result can be quite different without using the newlines as separators.
Just for this first prompt, let’s see a complete example for it:
For n=2, we select 2 examples: “I am happy” (with label joy) and “I am sad” (with label sadness).
And our text that we want the model to label will be “I think things will be alright”.
The prompt will look like this:
Classify into 4 labels: anger, joy, optimism, sadness
Text: I am happy
Label: joy
Text: I am sad
Label: sadness
Text: I think things will be alright
Label:
Let’s see how the models perform using this prompt.
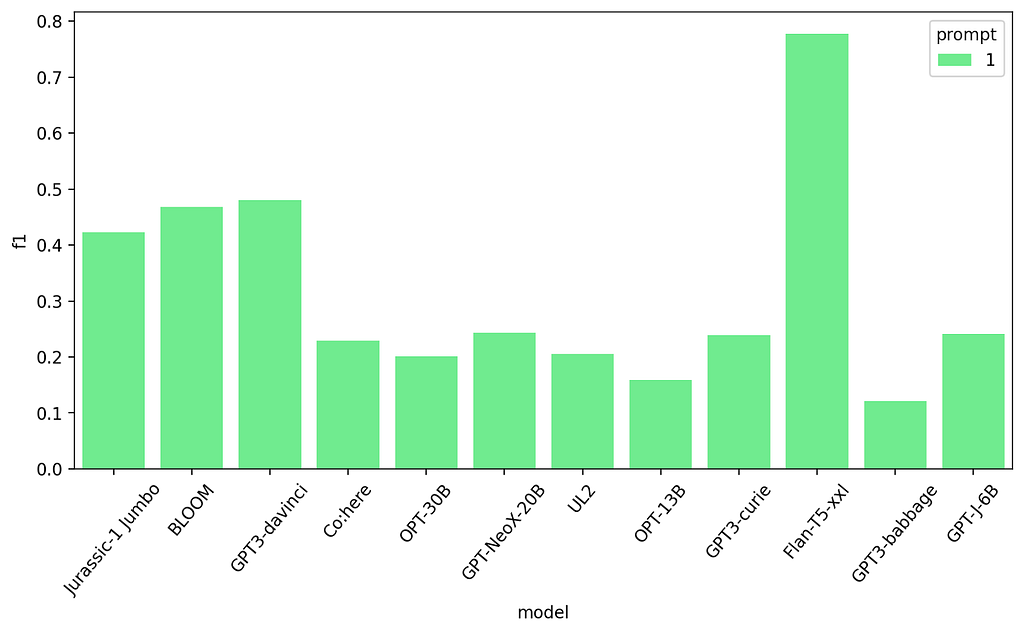
First prompt results — Text Classification task
This gives relatively good results for some of the bigger models, but not that great for the smaller ones (flan-t5 shines and we’ll talk more about it later).
Let’s add a bit more context to the description. We will do that by saying 2 additional things:
- Classify the “text”
- Classify it into only one of the 4 labels
This is the resulting prompt, changes are underlined:
Classify Text into one of 4 labels: anger, joy, optimism, sadness
Text: {text-n-shot}
Label: {label-n-shot}
…
Text: {current_text}
Label:
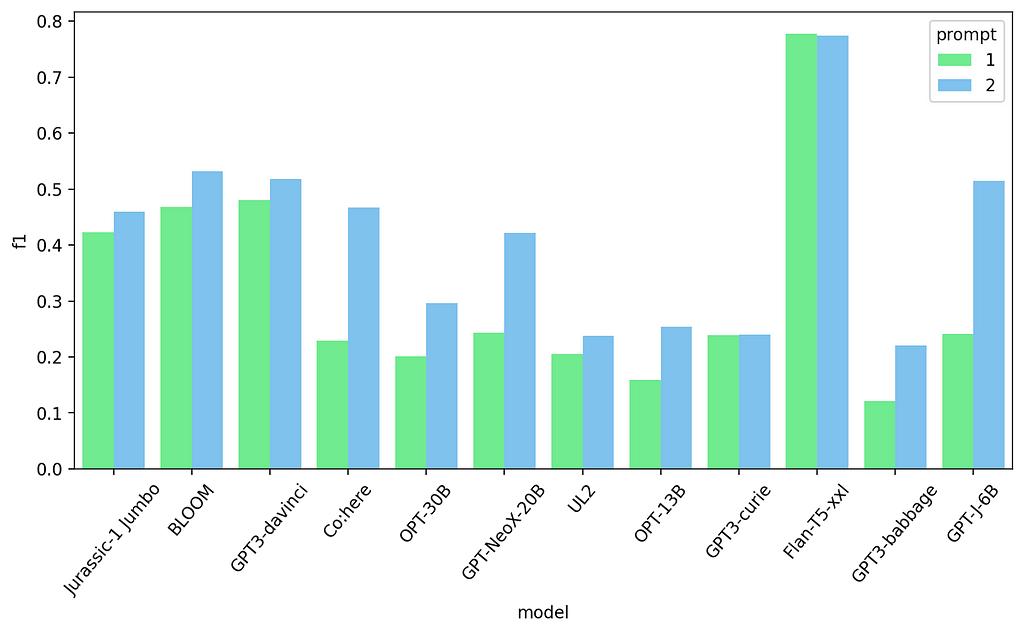
First and second prompt results — Text Classification task
Just this simple change already gives better results for most models, specially the smaller ones. Let’s try to further improve the results by being more specific. We can do that by referring to these inputs and outputs by what they really are: tweets and sentiments. Notice also I’m adding an “each” in the description.
Classify each Tweet into one of 4 sentiments: anger, joy, optimism, sadness
Tweet: {text-n-shot}
Sentiment: {label-n-shot}
…
Tweet: {current_text}
Sentiment:
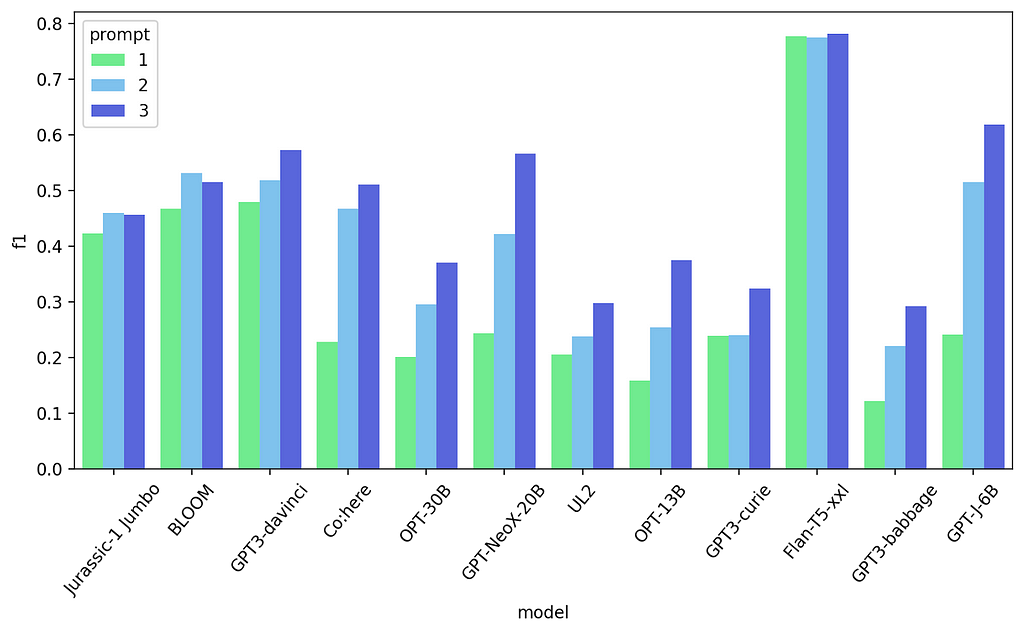
First 3 prompt results — Text classification task
This does even better for most models! Let’s do some more experiments, where could we try and improve? Maybe trying to better indicate the beginning and ending of the tweets text? Because the text isn’t really just alpha-numerical characters.
Classify each Tweet into one of 4 sentiments: anger, joy, optimism, sadness
Tweet: “””{text-n-shot}”””
Sentiment: {label-n-shot}
…
Tweet: “””{current_text}”””
Sentiment:
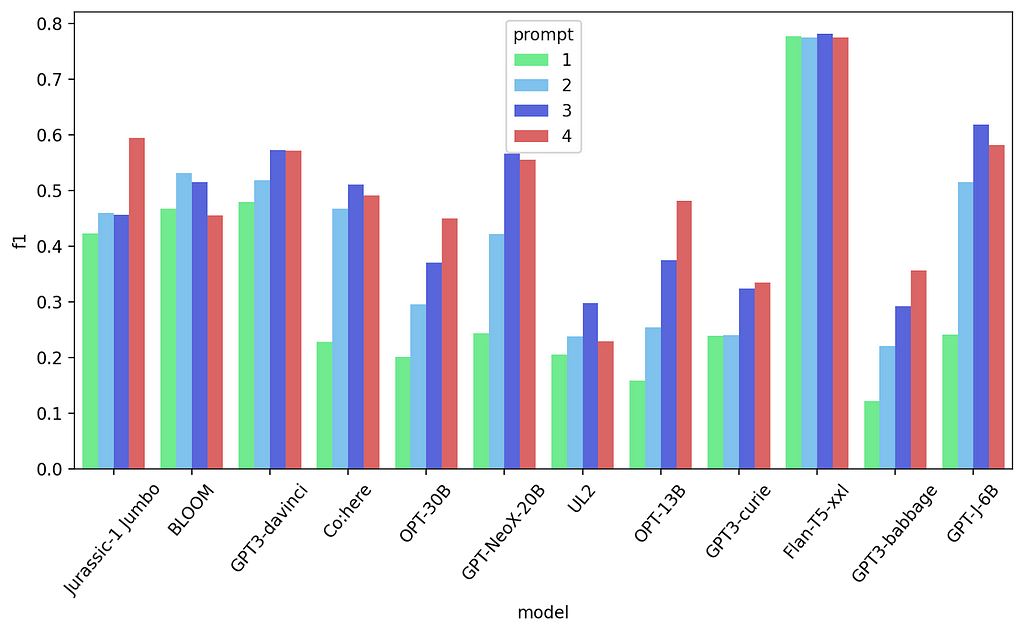
First 4 prompt results — Text classification task
This is the first change that didn’t improve performance across the board (although it still did for some of the models).
Let’s try one last change. Let’s reformulate the task description by actually using a common naming of this specific task “sentiment classification”:
Sentiment classify each Tweet into one of these sentiments: anger, joy, optimism, sadness
Tweet: {text-n-shot}
Sentiment: {label-n-shot}
…
Tweet: {current_text}
Label:
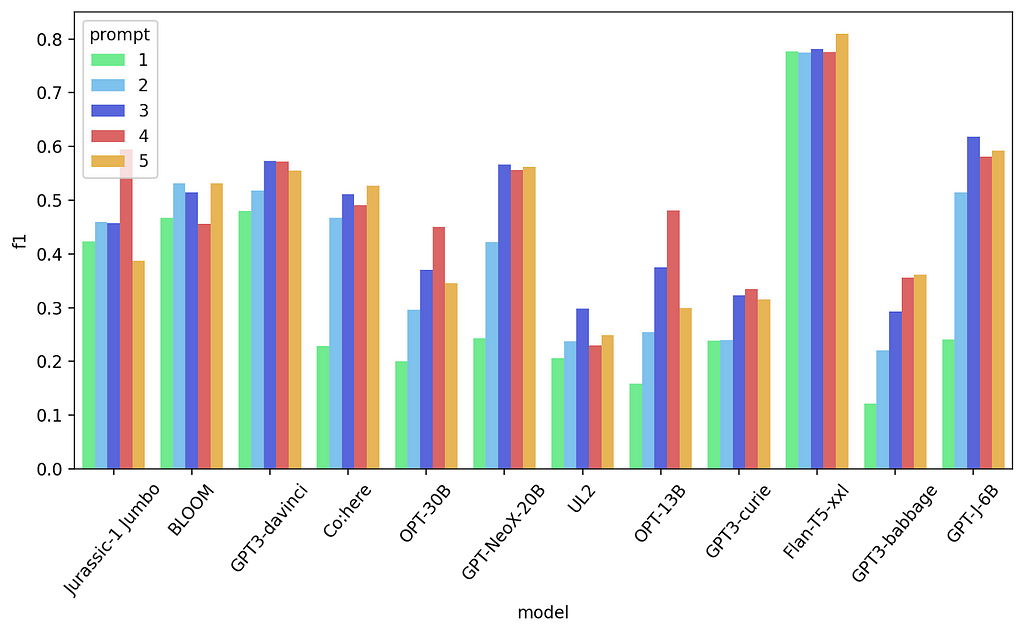
All 5 prompt results — Text classification task
Again, not better across the board but it is the best prompt for some models. You can try to experiment more, I’m certain you would be able to improve it further. But for now, I think I made my case in how much prompting matters.
Let’s look at another one of our tasks and go through the same process.
Named entity recognition
Let’s switch to named entity recognition which is a slightly more challenging task. We used the Few-NERD dataset. This is a fine-grained manually annotated dataset that has multiple levels of entities. We went just with the most general one of 8 entities: location, organization, person, product, art, building, event, misc
Arguably we can frame the task in multiple ways, for example just extracting the words that are entities is already simple named entity recognition. We opted for the slightly harder version of actually detecting the entity type for each entity.
So, for the text “I went to Central Park when I was at PyData in New York” it has to extract:
- Central Park — location
- PyData — event
- New York — location
How do we construct a prompt around this? One way is to expect the model to mark the words in the text with the entity types, and similar to before, by giving it a few examples the model should be able to “learn” the task.
Here is our first prompt:
Extract tags for art, building, event, location, organization, other, person, product
Text: I went to Central Park when I was at PyData in New York
Tags: I went to Central(location) Park(location) when I was at PyData(event) in New(location) York(location)
…
Text: {input text}
Tags:
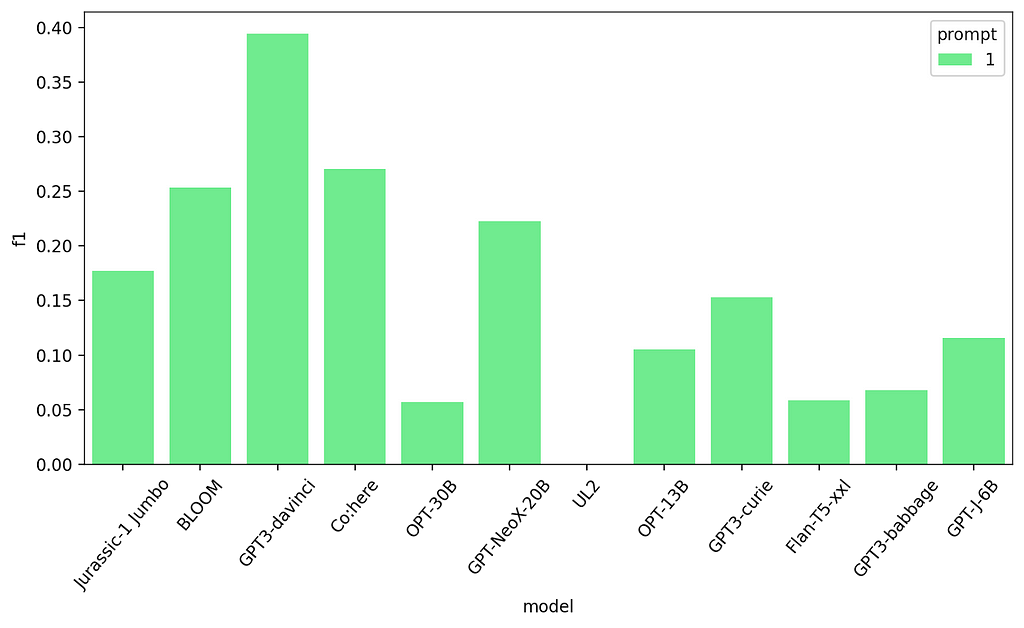
First prompt results — Named Entity Recognition
The bigger models in general seem to do better which is unsurprising. This task is harder so we can’t expect such big improvements as before, but let’s give it a try!
For the second prompt let’s modify the task description and also instead of “Tags” we’ll use “Marked Text”
For each text, mark tags from one of the categories: art, building, event, location, organization, other, person, product
Text: I went to Central Park when I was at PyData in New York
Marked Text: I went to Central(location) Park(location) when I was at PyData(event) in New(location) York(location)
…
Text: {input text}
Marked Text:
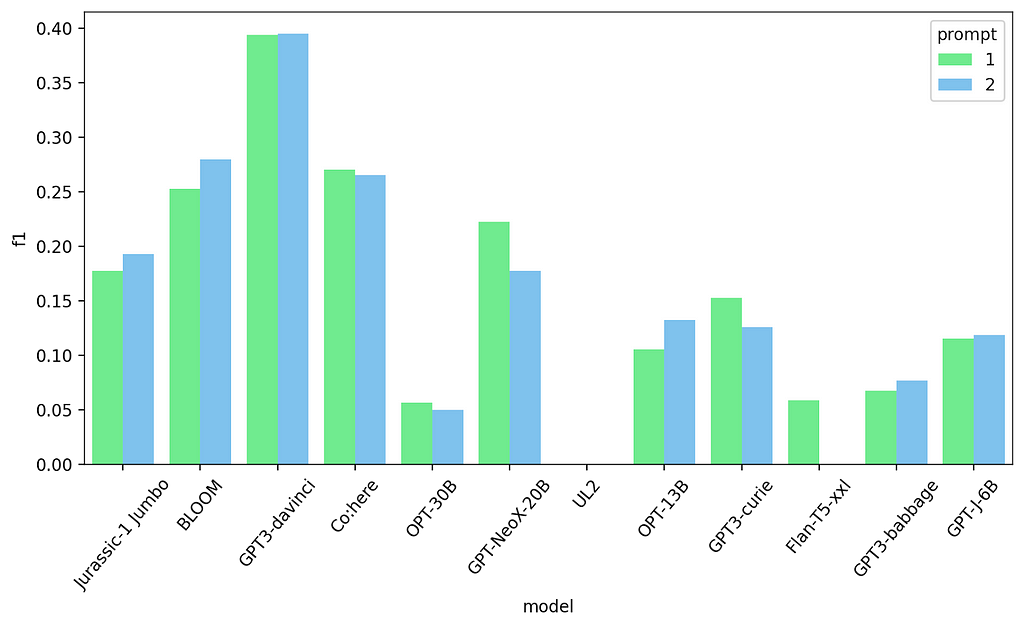
First 2 prompt results — Named Entity Recognition
This is a small improvement for 6 of the models and a slight decrease for 5 of them. So we still have a bit to go. What else can we change? Let’s explicitly say that these are “NER tags” ?
For each text, extract NER tags from the taxonomy: art, building, event, location, organization, other, person, product
Text: I went to Central Park when I was at PyData in New York
Marked Text: I went to Central(location) Park(location) when I was at PyData(event) in New(location) York(location)
…
Text: {input text}
Marked Text:
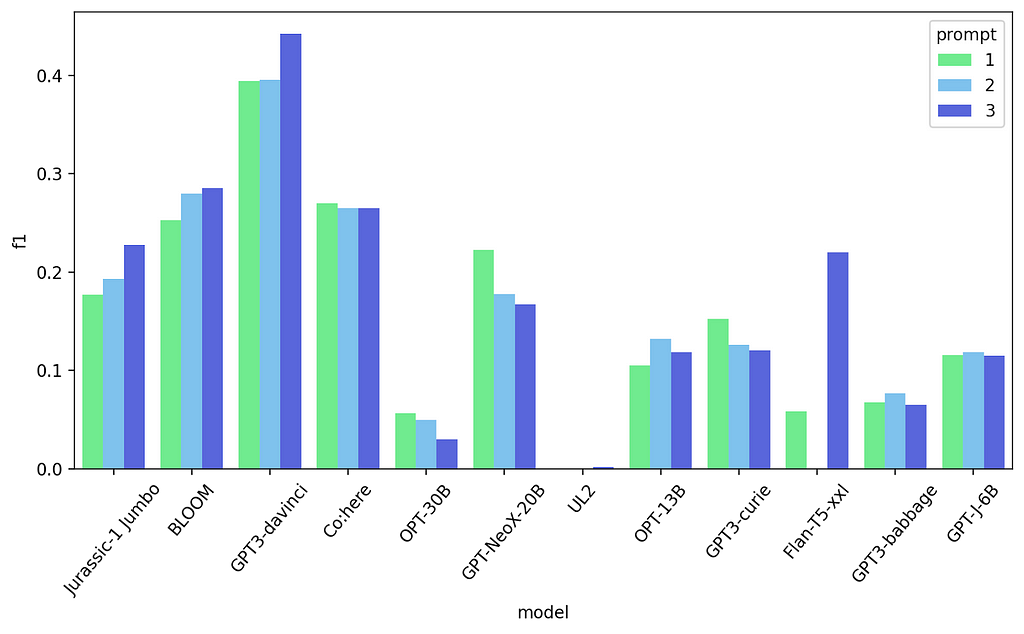
First 3prompt results — Named Entity Recognition
This is a bit better for some models, but again not good for others. It seems that the “NER” keyword is beneficial for some of the models. But it’s still not too good. Let’s try a different approach in the way we mark the entities. We’ll now mark the words using the data format used by the Rasa chatbot framework: which involves marking the entity with square brackets.
For each text, mark tags from one of the categories: art, building, event, location, organization, other, person, product
Text: I went to Central Park when I was at PyData in New York
Marked Text: I went to [Central](location) [Park](location) when I was at [PyData](event) in [New](location) [York](location)
…
Text: {input text}
Marked Text:
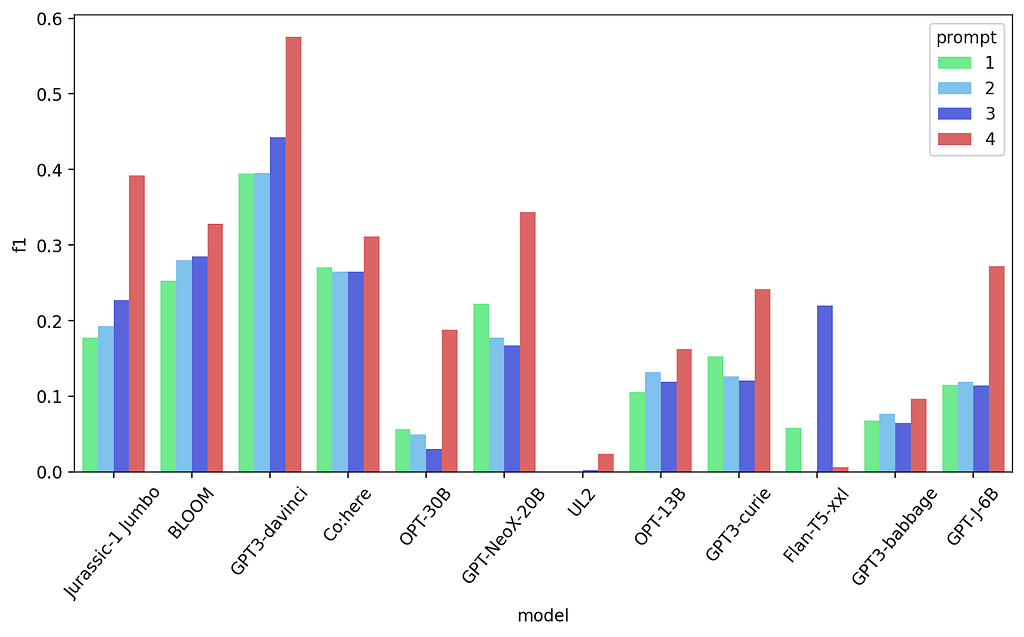
First 4 prompt results — Named Entity Recognition
This is an improvement almost across the board! It’s clear that demarcating the entities helped the models better understand what they have to do.
The last prompt variation is really just small changes to see if separating the description from the list of tags might help.
For each text, mark NER tags.
Tag categories: art, building, event, location, organization, other, person, product
Text: I went to Central Park when I was at PyData in New York
Marked Text: I went to [Central](location) [Park](location) when I was at [PyData](event) in [New](location) [York](location)
…
Text: {input text}
Marked Text:
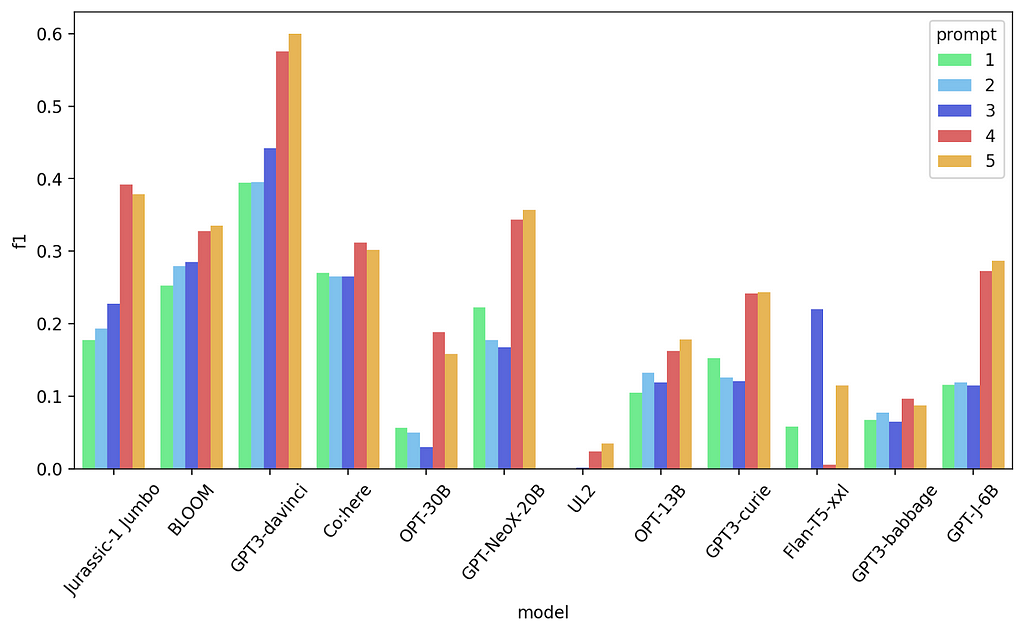
All prompt results — Named Entity Recognition
The last change again is split between models. For some it offered that extra edge, while for others not really. As we can see, even for a heavier task like named entity recognition, prompting can still make a pretty huge difference in results, but it still depends on us to select the correct one depending on the model.
Outro
Before closing remarks, I want to point to a very good source of prompts: PromptSource is a repository of thousands of prompts for hundreds of datasets. It can be a very good starting point for when you don’t know how a first variant of your prompt should look like.
There we have it. I hope I was able to give a good enough overview of how prompt engineering works and how you go about constructing prompts. You can look at the other prompts we used here.
Next blog we’ll look at all the results we got based on our experiments. Stay tuned as there’s some really interesting observations we extract that can help you take your prompt engineering to the next level!
Prompt Engineering — Part III — Examples of prompt construction was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.