Prototyping with Large Language Models
Categories:
Do we even need annotated data anymore?
Until recently, to get started with creating a machine learning model, you needed data specifically prepared for your task. Preparing data for training models is usually a manual and time consuming process, during which domain experts add instructive labels to the data which the model tries to learn. With the advent of Large Language Models (LLM) like ChatGPT and GPT4, this process may not always be necessary to create a first working model.
There are at least three ways that LLMs can help you circumvent the requirement of manually preparing data for your application
- Using LLM in a zero shot fashion for your application
- Creating synthetic data to train your first model
- Label your data using a LLM
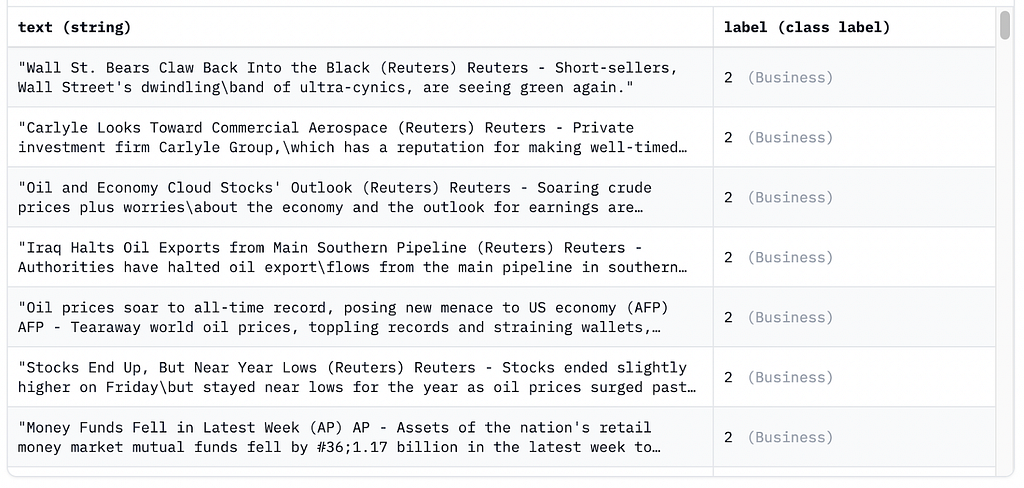
Let’s see each of those ways in more detail. We will use ChatGPT and ag_news for demonstration. Ag_news is a dataset consisting of news articles tagged thematically as Business, World, Sports or Sci/Tech.
Zero shot LLM
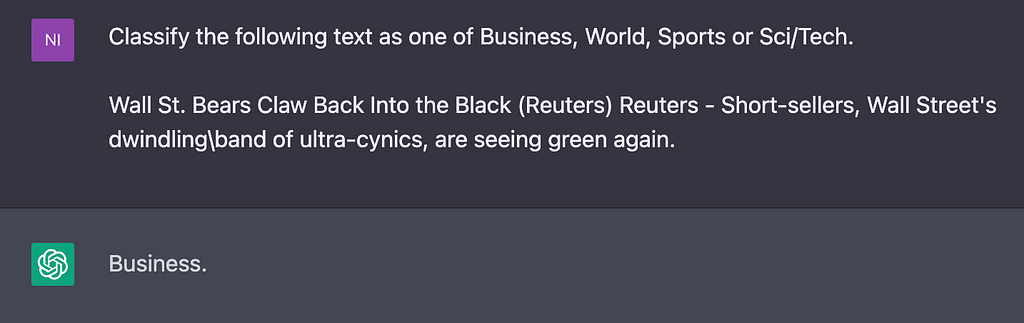
The simplest way to use a Large Language Model for your application is to ask the model to perform the task without giving it any examples of the correct input / outputs you expect. This is referred to as zero shot in AI terminology.
Assuming you are happy with the performance of the model, you can integrate it into your application. The major downside with this approach is cost. Using a LLM as your machine learning model may be up to 100x more expensive than using a smaller more specialized model.
Synthetic data
Another route is to create synthetic data and use them to train a smaller model to perform the task.

With this approach you need to ensure that the data are diverse, so you might need to guide the model towards certain directions, and then remove examples that are too similar to each other.
Label with LLM
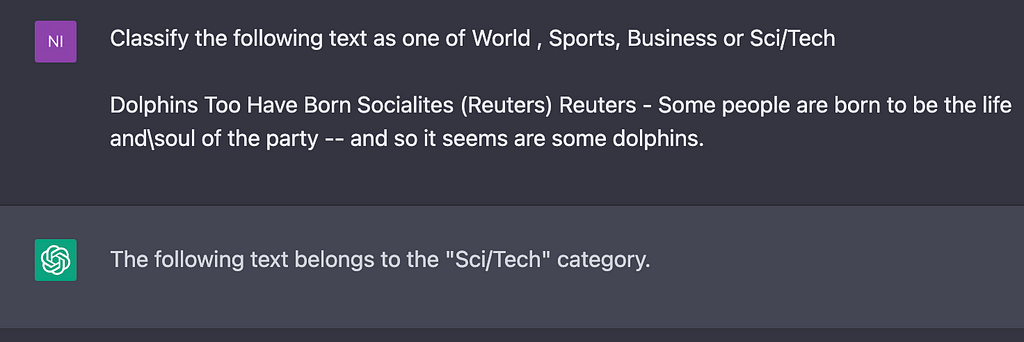
Finally, instead of using domain experts to add labels to your data, you can use a LLM instead. Then you can use that data to train a smaller model. Prompting the models to give you labels is similar to zero shot LLM.
Performance
Here is how these different approaches perform on the ag_news dataset. We use SetFit to train smaller models using the synthetic data and the data labeled from the LLM. SetFit is an extremely sample efficient technique that we talked about in our previous blog post “Eight examples is all you need”. We are using SetFit to minimize the amount of data we need to annotate using the LLM. We also use GPT3 (text-davinci-003) for our experiments.
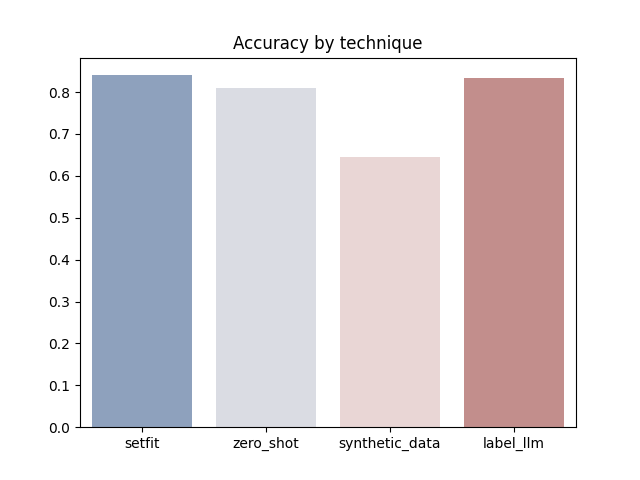
GPT3 seems to work well out of the box in a zero shot fashion. It also seems that training a smaller model on data labeled from GPT3 works equally well 💥 Out of all the approaches, creating synthetic data seems to be the hardest to make work for the reasons we mentioned earlier. Even so, the very fact that it works is remarkable given that the only information we gave to GPT was that the dataset consists of one sentence news articles of certain topics.
It is worth mentioning that the dataset used is most probably part of the training dataset of GPT3 so we are overestimating its performance but probably by not by too much, judging from the latest technical report from OpenAI that mentions that performance seems to be close in tasks that have high and no contamination. And even though the performance is not exactly state of the art, which is closer to 94% on this dataset, it still enables you to build a great working model to start with.
I hope you enjoyed this post. Our code for these experiments can be found here https://github.com/MantisAI/experiments/tree/main/data%5Fllm. If you are interested in using Large Language Models in a project or want to discuss any of the topics above, do not hesitate to send us an email at hi@mantisnlp.com.
Prototyping with Large Language Models 🪄 was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.