Automatic Prompt Engineering (Part I: Main Concepts)
Categories:
This is the first of a series of 4 blog posts, where we will be discussing the Prompt Engineering paradigm, how to create an automated workflow for Prompt Engineering Automation, share some hands-on code and some conclusions.
In this first post, we will cover what Prompt Engineering looks like, which are the companies already offering solutions, and how Prompt Engineering can improve the quality of our prompts, reducing hallucinations, in a specific use case: Retrieval-Augmented Generative (RAG) Models. Let’s start!
The Prompt Engineering paradigm
In today’s rapidly evolving technological landscape, Natural Language Processing (NLP) models have witnessed tremendous advancements, empowering machines to comprehend and generate human-like text.
Language models, such as OpenAI’s GPT-4, are designed to generate coherent responses based on the information provided in their prompts.
A prompt is a very trendy concept in Artificial Intelligence (AI), particularly used in NLP and Computer Vision. By Prompt Engineering (PE) (see our previous Mantis NLP post about this topic — Part I, Part II and Part III) we mean a new paradigm, consisting of providing an AI model with the description of the task that the AI is supposed to accomplish, e.g. as a question, in comparison with traditional approaches where you pretrain the model on annotated data to carry out that task.
Crafting an effective prompt can be a challenging task, requiring careful consideration of wording, structure, and context. Inadequate prompts may lead to ambiguous, inaccurate responses, hindering the model’s ability to provide meaningful information.
Some companies offer (paid) Prompt Engineering solutions. Let’s list some of them.
Prompt Engineering Solutions
The growing interest in achieving high quality prompts can be easily witnessed by checking recent additions to NLP solutions:
- Jina AI Prompt Perfect , a paid solution that does Automatic Prompt Optimization. They claim that, with Prompt Perfect, you can Unlock the full potential of prompt engineering […] without the complexity and Leverage the power of [Prompt Perfect] to consistently achieve superior results and enhance the capabilities of LLMs and LMs.
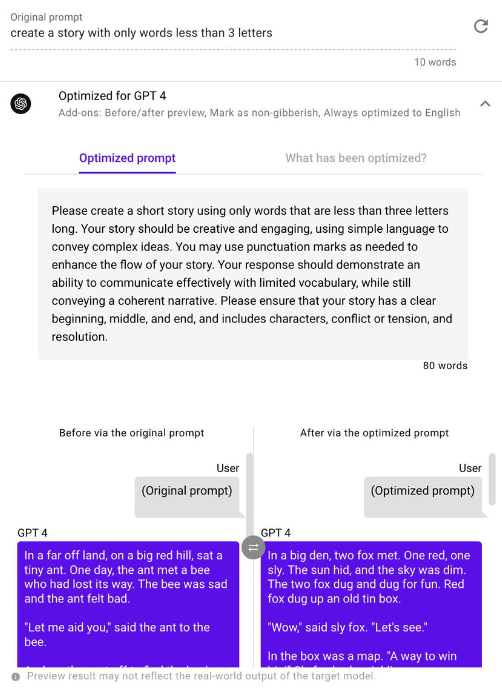
- Galileo AI Prompt Inspector (paid with a free option) gives you information about the reliability of your prompts. They highlight the ability of their product to Detect model hallucinations, find the best prompt, inspect data errors while fine-tuning and Minimize hallucinations and costs and find the ‘right’ prompt fast.
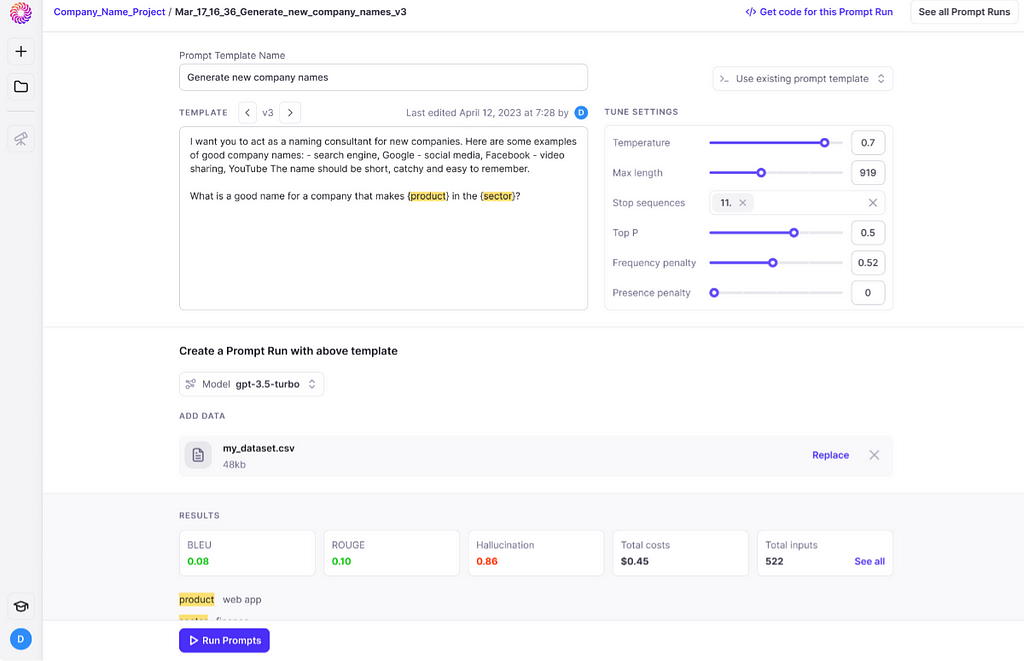
- Explosion.ai’s Prodigy (paid solution) has released both A/B testing for prompts and new prompt tournament capabilities. The tournament approach is the following: Instead of comparing two examples with each other, as in A/B testing, you can also create a tournament to compare any number of prompts. After, a Glicko ranking system will be triggered to keep track of the best performing candidate and will select duels between prompts accordingly.
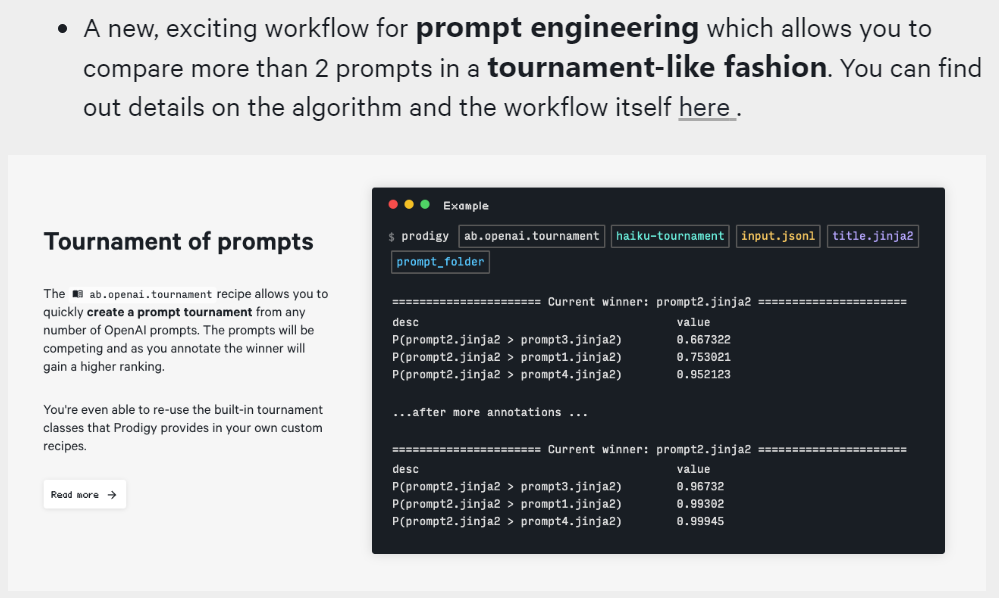
In this first post, we are going to provide you with the foundations behind Automatic Prompt Engineering (APE), aggregating the latest papers and features, so that you can build your own APE methodology. More specifically, we will focus on one use case: Retrieval-augmented Generative models (RAG).
Retrieval-Augmented Generative Models
A RAG system (not to be confused with RAG pretrained model) is an LLM-based process which uses a question and several knowledge statements from a database to generate a reliable answer. We specifically chose this use case due to its popularity and the concerns raised against the reliability of the answers, hallucinations and false positives.
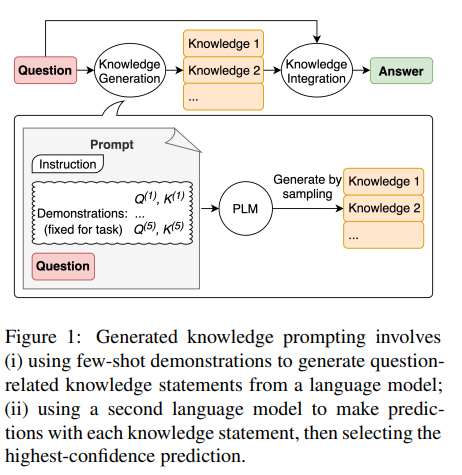
Early works on Information Retrieval Augmentation improving text generation were documented in papers as Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks and Generated Knowledge Prompting for Commonsense Reasoning before even ChatGPT was released.
The idea is simple: providing evidence as pieces of knowledge to a model, significantly improves the answer. This is basically a mechanism to reduce the problems generated by:
- A total lack of data: the LLM did not see data to answer your question, so it will probably state that it can’t answer the question.
- A partial lack of data: the LLM did not see sufficient data to provide an answer. However, in the worst case scenario, it will answer anyway with a hallucination.
- Outdated data: GPT3.5 was trained with data before 2021.
- Model not finetuned to your needs: the LLM may know about the question but the answer it provides does not satisfy your business needs.
The latest paper of the two mentioned above applies Knowledge Generation (using another LLM) to create evidence for the Language Model to generate an answer.
However, the most recent and easy approach is to use an internal knowledge (data) base with business documentation to guide the LLM when creating the response.
How to implement a RAG?
Imagine that you want to implement an internal chatbot in your business, to leverage all your company documentation and help to solve questions which may arise. You have documentation stored in a database, so the pieces of knowledge for the Retrieval-augmented Generation will come from there.
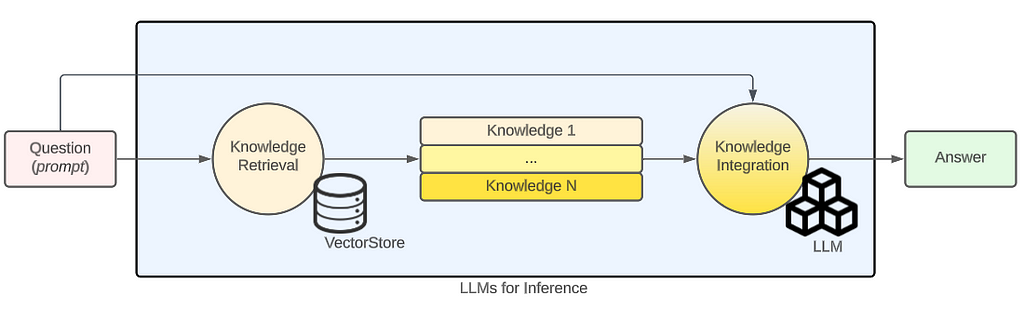
The most common approach is to use a specific type of database called a Vector Store, where all your documentation is stored, and an LLM to chat over the documents. This has been “traditionally” carried out in three steps:
- Embeddings Calculation. Your documents are processed using a LLM to calculate the Embeddings, a numerical representation of them, and stored in a Vector Store. The Vector Store will act as a database to store the embeddings during indexing time, and retrieve them during answer generation time.
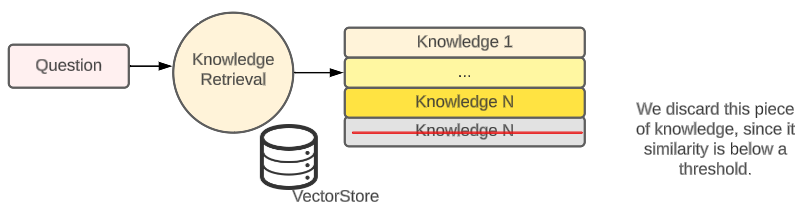
- Knowledge Retrieval. During answer generation time, a question triggers a similarity search in the Vector Store, which retrieves the most similar top-X results stored in your Vector Store;
- Knowledge Integration. Finally, an LLM is used to combine those responses and write an answer which matches the question asked.
There are many things which can go wrong in the process. One clear example is the absence of relevant information to answer the question. But that can be easily tackled by filtering out those results from the similarity search with low similarity metrics.
However, what happens if a problem arises in the creation of the answer by the LLM? How good is the answer? Are we sure it truthfully answers the question? How could we know if the LLM is making conclusions outside of the limits of your data?
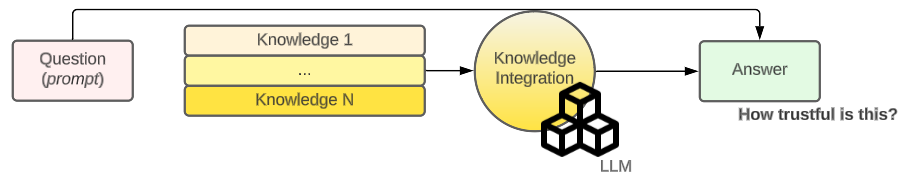
Reducing the temperature (or level or creativity) may help, but does not guarantee the absence of one of the most loved phenomena in the NLP community — hallucinations.
Hallucinations
Hallucinations in LLMs are generally a result of certain underlying factors or causes. While LLMs have been designed to generate coherent and contextually appropriate text, they can occasionally produce hallucinatory or nonsensical responses.
Here are some potential causes of hallucinations in LLMs:
- 1. Lack of Knowledge. The LLM did not seeenough information about the question during training time**.** In _traditional_ approaches we used to get more data and retrain. But with LLMs that is not always an option due to prohibitive costs of retraining. Other **non-prompt related problems** are **training data bias** / **sub** or **over-optimization**, **noise**, etc.
- 2. Lack of Context. LLMs rely heavily on the prompts to generate responses. If the prompt is insufficient or lacks necessary context, the model may struggle to produce accurate or sensible outputs. Without clear contextual cues, the LLM may fill in the gaps with fabricated or hallucinatory information.
- 3. Ambiguity. Ambiguous or poorly constructed prompts can lead to misinterpretation by LLMs, resulting in hallucinatory outputs. The model may attempt to make sense of the ambiguous input by generating imaginative or nonsensical responses that are not aligned with the user’s intentions.
Tackling point 1 is out of the reach for most of the companies using API-based NLP (e.g. OpenAI’s GPT services), since they don’t have access to the model. So the only way to properly prevent hallucinations in an LLM consumed via API is tackling points 2 and 3, and this is achieved using Prompt Engineering (PE) techniques.
Now that we covered the main concepts, let’s deep dive into what different papers propose in terms of APE building workflows, in the second part of the blog.
Want to know more?
I hope you enjoyed this post. Remember this is a series of 4 posts and it has a continuation. Make sure you read them in a sequential order.
If you need help in your NLP processes, MantisNLP will be glad to help! Feel free to reach out at hi@mantisnlp.com and stay tuned for more blog posts!

Automatic Prompt Engineering (Part I: Main Concepts) was originally published in MantisNLP on Medium, where people are continuing the conversation by highlighting and responding to this story.